↧
NGUI_打字机效果_011
↧
Linux命令 - 查看文件内容 tail 命令
Linux命令 - 查看文件内容 tail 命令
1.介绍
tail命令用于输入文件中的尾部内容。tail命令默认在屏幕上显示指定文件的末尾10行。如果给定的文件不止一个,则在显示的每个文件前面加一个文件名标题。如果没有指定文件或者文件名为“-”,则读取标准输入。2.命令提供的选项列表
--retry:即是在tail命令启动时,文件不可访问或者文件稍后变得不可访问,都始终尝试打开文件。使用此选项时需要与选项“——follow=name”连用;
-c或——bytes=:输出文件尾部的N(N为整数)个字节内容;
-f或;--follow:显示文件最新追加的内容。“name”表示以文件名的方式监视文件的变化。“-f”与“-fdescriptor”等效;
-F:与选项“-follow=name”和“--retry"连用时功能相同;
// 如果-n参数带加号,如 -n +20,将会打开文件从第20行到最后的内容,你也可以指定其它参数,b,k,m,意思是,1b,1kb,1mb
-n或——line=:输出文件的尾部N(N位数字)行内容。
--pid=<进程号>:与“-f”选项连用,当指定的进程号的进程终止后,自动退出tail命令;
-q或——quiet或——silent:当有多个文件参数时,不输出各个文件名;
-s<秒数>或——sleep-interal=<秒数>:与“-f”选项连用,指定监视文件变化时间隔的秒数;
-v或——verbose:当有多个文件参数时,总是输出各个文件名;
--help:显示指令的帮助信息;
--version:显示指令的版本信息。
3.常见应用
// 跟踪tomcat的控制台输出
// catalina.out 在tomcat的安装目录下的logs文件夹中
// 你可以通过ctrl + c命令来退出监控
tail -f catalina.out
// 读取文件的最后10行
tail 文件名
作者:qq_15071263 发表于2017/9/12 19:51:22 原文链接
阅读:155 评论:0 查看评论
↧
↧
linux命令_系统管理_useradd(adduser)
宽为限 紧用功 功夫到 滞塞通
adduser
功能说明:
useradd命令用于Linux中创建的新的系统用户或更新预设的使用者资料。useradd可用来建立用户帐号。帐号建好之后,再用passwd设定帐号的密码.而可用userdel删除帐号。使用useradd指令所建立的帐号,实际上是保存在/etc/passwd文本文件中。 在Slackware中,adduser指令是个script程序,利用交谈的方式取得输入的用户帐号资料,然后再交由真正建立帐号的useradd命令建立新用户,如此可方便管理员建立用户帐号。在Red Hat Linux中,adduser命令则是useradd命令的符号连接,两者实际上是同一个指令(经由符号连结 symbolic link)。
使用权限:系统管理员。
语法:
useradd [-mMnr][-c <备注>][-d <登入目录>][-e <有效期限>][-f <缓冲天数>][-g <群组>][-G <群组>][-s <shell>][-u <uid>][用户帐号]或
useradd -D [-b][-e <有效期限>][-f <缓冲天数>][-g <群组>][-G <群组>][-s <shell>]
参数说明:
-c<备注>:加上备注文字。备注文字会保存在passwd的备注栏位中;
-d<登入目录>:指定用户登入时的启始目录;
-D:变更预设值;
-e<有效期限>:指定帐号的有效期限(格式为 YYYY-MM-DD);
-f<缓冲天数>:指定在密码过期后多少天即关闭该帐号;
-g<群组>:指定用户所属的群组;
-G<群组>:指定用户所属的附加群组;
-m:自动建立用户的登入目录;
-M:不要自动建立用户的登入目录;
-n:取消建立以用户名称为名的群组;
-r:建立系统帐号;
-s:指定用户登入后所使用的shell;
-u:指定用户id。实例:
添加一个一般用户
# useradd gm //添加用户gm为添加的用户指定相应的用户组
# useradd -g root kk //添加用户kk,并指定用户所在的组为root用户组创建一个系统用户
# useradd -r kk //创建一个系统用户kk为新添加的用户指定/home目录
# useradd -d /home/myf kk //新添加用户kk,其home目录为/home/myf
//当用户名kk登录主机时,系统进入的默认目录为/home/myf建立一个新用户账户,并设置ID
# useradd caojh -u 544需要说明的是,设定ID值时尽量要大于500,以免冲突。因为Linux安装后会建立一些特殊用户,一般0到499之间的值留给bin、mail这样的系统账号。
作者:GMingZhou 发表于2017/9/12 19:53:24 原文链接
阅读:179 评论:0 查看评论
↧
matlab2c使用c++实现matlab函数系列教程-load函数
全栈工程师开发手册 (作者:栾鹏)
matlab2c动态链接库下载
matlab库函数大全
matlab2c基础教程
matlab2c开发全解教程
matlab2c调用方法:
1、下载matlab2c动态链接库
2、将matlab2c.dll、matlab2c.lib和matlab2c.h放到项目头文件目录下
3、在cpp文件中引入下面的代码
#include "Matlab2c.h"
#pragma comment(lib,"Matlab2c.lib")
using namespace Matlab2c;matlab中load函数简介
1、load函数:
从文件中读取矩阵数据
2、用法说明
A= load (‘e:\123.txt’) 从文件123.txt中读取矩阵
load的c++源码实现
从文件中加载数据
文件内容为矩阵数组形式,元素间通过空格间隔
Matrix Matlab2c::load(string path){
std::ifstream fin(path, std::ios::in);
char line[1024]={0};
string x="0";
vector<vector<double>> alldata;
while(fin.getline(line, sizeof(line),'\n'))
{
vector<double> onerow;
std::stringstream word(line);
while(word>>x)
{
onerow.push_back(std::stod(x));
}
if (onerow.size()!=0)
{
alldata.push_back(onerow);
}
}
fin.close();
Matrix p(alldata);
return p;
}
load函数的使用测试
数据文件data.txt
11 22 33 44
22 33 44 55
33 44 55 66
示例代码:
#include "Matlab2c.h"
#pragma comment(lib,"Matlab2c.lib")
using namespace Matlab2c;
int main()
{
Matrix bb=Matlab2c::load("data.txt");
cout<<bb.toString()<<endl;
system("pause");
return 0;
}
作者:luanpeng825485697 发表于2017/9/12 19:54:04 原文链接
阅读:185 评论:0 查看评论
↧
matlab2c使用c++实现matlab函数系列教程-save函数
全栈工程师开发手册 (作者:栾鹏)
matlab2c动态链接库下载
matlab库函数大全
matlab2c基础教程
matlab2c开发全解教程
matlab2c调用方法:
1、下载matlab2c动态链接库
2、将matlab2c.dll、matlab2c.lib和matlab2c.h放到项目头文件目录下
3、在cpp文件中引入下面的代码
#include "Matlab2c.h"
#pragma comment(lib,"Matlab2c.lib")
using namespace Matlab2c;matlab中save函数简介
1、save函数:
将矩阵保存到文件
2、用法说明
save(‘filename.txt’,var,’-ascii’), 其中。filename是保存后的文件名,var是要保存的数据等,-ascii等是保存模式,表示是ASCii码的形式保存的
save的c++源码实现
将矩阵数据写入文件
输入:文件地址,要写入的矩阵
void Matlab2c::save(string path,Matrix& a){
std::ofstream fout(path, std::ios::out);
for (int i=0;i<a.row;i++)
{
int j=0;
for (j=0;j<a.column-1;j++)
{
fout<<a(i,j)<<" ";
}
fout<<a(i,j);
fout<<"\n";
}
fout.close();
}
save函数的使用测试
#include "Matlab2c.h"
#pragma comment(lib,"Matlab2c.lib")
using namespace Matlab2c;
int main()
{
double a[]={1.1,2.2,3.3,4.4,5.5,6.6};
Matrix aa(2,3,a);
Matlab2c::save("data.txt",aa);
system("pause");
return 0;
}
作者:luanpeng825485697 发表于2017/9/12 20:08:08 原文链接
阅读:192 评论:0 查看评论
↧
↧
Go实战--使用golang开发Windows Gui桌面程序(lxn/walk)
生命不止,继续 go go go!!!
golang官方并没有提供Windows gui库,但是今天还是要跟大家分享一下使用golang开发Windows桌面程序,当然又是面向github编程了。
知乎上有一个问答:
golang为什么没有官方的gui包?
这里,主要使用第三方库lxn/walk,进行Windows GUI编程。
lxn/walk
github地址:
https://github.com/lxn/walk
star:
2018
描述:
A Windows GUI toolkit for the Go Programming Language
获取:
go get github.com/lxn/walk例子:
main.go
package main
import (
"github.com/lxn/walk"
. "github.com/lxn/walk/declarative"
"strings"
)
func main() {
var inTE, outTE *walk.TextEdit
MainWindow{
Title: "SCREAMO",
MinSize: Size{600, 400},
Layout: VBox{},
Children: []Widget{
HSplitter{
Children: []Widget{
TextEdit{AssignTo: &inTE},
TextEdit{AssignTo: &outTE, ReadOnly: true},
},
},
PushButton{
Text: "SCREAM",
OnClicked: func() {
outTE.SetText(strings.ToUpper(inTE.Text()))
},
},
},
}.Run()
}go build生成go_windows_gui.exe。
go_windows_gui.exe.manifest
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<assembly xmlns="urn:schemas-microsoft-com:asm.v1" manifestVersion="1.0">
<assemblyIdentity version="1.0.0.0" processorArchitecture="*" name="SomeFunkyNameHere" type="win32"/>
<dependency>
<dependentAssembly>
<assemblyIdentity type="win32" name="Microsoft.Windows.Common-Controls" version="6.0.0.0" processorArchitecture="*" publicKeyToken="6595b64144ccf1df" language="*"/>
</dependentAssembly>
</dependency>
</assembly>运行结果:
什么是manifest
上面提到了manifest,这是干什么的呢?
https://msdn.microsoft.com/en-us/library/windows/desktop/aa375365(v=vs.85).aspx
介绍:
Manifests are XML files that accompany and describe side-by-side assemblies or isolated applications. Manifests uniquely identify the assembly through the assembly’s assemblyIdentity element. They contain information used for binding and activation, such as COM classes, interfaces, and type libraries, that has traditionally been stored in the registry. Manifests also specify the files that make up the assembly and may include Windows classes if the assembly author wants them to be versioned. Side-by-side assemblies are not registered on the system, but are available to applications and other assemblies on the system that specify dependencies in manifest files.
是一种xml文件,标明所依赖的side-by-side组建。
如果用VS开发,可以Set通过porperty->configuration properties->linker->manifest file->Generate manifest To Yes来自动创建manifest来指定系统的和CRT的assembly版本。
详解
观察上面的manifest文件:
<xml>这是xml声明:
版本号----<?xml version="1.0"?>。
这是必选项。 尽管以后的 XML 版本可能会更改该数字,但是 1.0 是当前的版本。
编码声明------<?xml version="1.0" encoding="UTF-8"?>
这是可选项。 如果使用编码声明,必须紧接在 XML 声明的版本信息之后,并且必须包含代表现有字符编码的值。
standalone表示该xml是不是独立的,如果是yes,则表示这个XML文档时独立的,不能引用外部的DTD规范文件;如果是no,则该XML文档不是独立的,表示可以用外部的DTD规范文档。<dependency>这一部分指明了其依赖于一个库:
<assemblyIdentity>属性里面还分别是:
type----系统类型,
version----版本号,
processorArchitecture----平台环境,
publicKeyToken----公匙应用
做一个巨丑无比的登录框
这里用到了LineEdit、LineEdit控件
package main
import (
"github.com/lxn/walk"
. "github.com/lxn/walk/declarative"
)
func main() {
var usernameTE, passwordTE *walk.LineEdit
MainWindow{
Title: "登录",
MinSize: Size{270, 290},
Layout: VBox{},
Children: []Widget{
Composite{
Layout: Grid{Columns: 2, Spacing: 10},
Children: []Widget{
VSplitter{
Children: []Widget{
Label{
Text: "用户名",
},
},
},
VSplitter{
Children: []Widget{
LineEdit{
MinSize: Size{160, 0},
AssignTo: &usernameTE,
},
},
},
VSplitter{
Children: []Widget{
Label{MaxSize: Size{160, 40},
Text: "密码",
},
},
},
VSplitter{
Children: []Widget{
LineEdit{
MinSize: Size{160, 0},
AssignTo: &passwordTE,
},
},
},
},
},
PushButton{
Text: "登录",
MinSize: Size{120, 50},
OnClicked: func() {
if usernameTE.Text() == "" {
var tmp walk.Form
walk.MsgBox(tmp, "用户名为空", "", walk.MsgBoxIconInformation)
return
}
if passwordTE.Text() == "" {
var tmp walk.Form
walk.MsgBox(tmp, "密码为空", "", walk.MsgBoxIconInformation)
return
}
},
},
},
}.Run()
}
效果:
TableView的使用
这里主要使用的是TableView控件,代码参考github:
package main
import (
"fmt"
"sort"
"github.com/lxn/walk"
. "github.com/lxn/walk/declarative"
)
type Condom struct {
Index int
Name string
Price int
checked bool
}
type CondomModel struct {
walk.TableModelBase
walk.SorterBase
sortColumn int
sortOrder walk.SortOrder
items []*Condom
}
func (m *CondomModel) RowCount() int {
return len(m.items)
}
func (m *CondomModel) Value(row, col int) interface{} {
item := m.items[row]
switch col {
case 0:
return item.Index
case 1:
return item.Name
case 2:
return item.Price
}
panic("unexpected col")
}
func (m *CondomModel) Checked(row int) bool {
return m.items[row].checked
}
func (m *CondomModel) SetChecked(row int, checked bool) error {
m.items[row].checked = checked
return nil
}
func (m *CondomModel) Sort(col int, order walk.SortOrder) error {
m.sortColumn, m.sortOrder = col, order
sort.Stable(m)
return m.SorterBase.Sort(col, order)
}
func (m *CondomModel) Len() int {
return len(m.items)
}
func (m *CondomModel) Less(i, j int) bool {
a, b := m.items[i], m.items[j]
c := func(ls bool) bool {
if m.sortOrder == walk.SortAscending {
return ls
}
return !ls
}
switch m.sortColumn {
case 0:
return c(a.Index < b.Index)
case 1:
return c(a.Name < b.Name)
case 2:
return c(a.Price < b.Price)
}
panic("unreachable")
}
func (m *CondomModel) Swap(i, j int) {
m.items[i], m.items[j] = m.items[j], m.items[i]
}
func NewCondomModel() *CondomModel {
m := new(CondomModel)
m.items = make([]*Condom, 3)
m.items[0] = &Condom{
Index: 0,
Name: "杜蕾斯",
Price: 20,
}
m.items[1] = &Condom{
Index: 1,
Name: "杰士邦",
Price: 18,
}
m.items[2] = &Condom{
Index: 2,
Name: "冈本",
Price: 19,
}
return m
}
type CondomMainWindow struct {
*walk.MainWindow
model *CondomModel
tv *walk.TableView
}
func main() {
mw := &CondomMainWindow{model: NewCondomModel()}
MainWindow{
AssignTo: &mw.MainWindow,
Title: "Condom展示",
Size: Size{800, 600},
Layout: VBox{},
Children: []Widget{
Composite{
Layout: HBox{MarginsZero: true},
Children: []Widget{
HSpacer{},
PushButton{
Text: "Add",
OnClicked: func() {
mw.model.items = append(mw.model.items, &Condom{
Index: mw.model.Len() + 1,
Name: "第六感",
Price: mw.model.Len() * 5,
})
mw.model.PublishRowsReset()
mw.tv.SetSelectedIndexes([]int{})
},
},
PushButton{
Text: "Delete",
OnClicked: func() {
items := []*Condom{}
remove := mw.tv.SelectedIndexes()
for i, x := range mw.model.items {
remove_ok := false
for _, j := range remove {
if i == j {
remove_ok = true
}
}
if !remove_ok {
items = append(items, x)
}
}
mw.model.items = items
mw.model.PublishRowsReset()
mw.tv.SetSelectedIndexes([]int{})
},
},
PushButton{
Text: "ExecChecked",
OnClicked: func() {
for _, x := range mw.model.items {
if x.checked {
fmt.Printf("checked: %v\n", x)
}
}
fmt.Println()
},
},
PushButton{
Text: "AddPriceChecked",
OnClicked: func() {
for i, x := range mw.model.items {
if x.checked {
x.Price++
mw.model.PublishRowChanged(i)
}
}
},
},
},
},
Composite{
Layout: VBox{},
ContextMenuItems: []MenuItem{
Action{
Text: "I&nfo",
OnTriggered: mw.tv_ItemActivated,
},
Action{
Text: "E&xit",
OnTriggered: func() {
mw.Close()
},
},
},
Children: []Widget{
TableView{
AssignTo: &mw.tv,
CheckBoxes: true,
ColumnsOrderable: true,
MultiSelection: true,
Columns: []TableViewColumn{
{Title: "编号"},
{Title: "名称"},
{Title: "价格"},
},
Model: mw.model,
OnCurrentIndexChanged: func() {
i := mw.tv.CurrentIndex()
if 0 <= i {
fmt.Printf("OnCurrentIndexChanged: %v\n", mw.model.items[i].Name)
}
},
OnItemActivated: mw.tv_ItemActivated,
},
},
},
},
}.Run()
}
func (mw *CondomMainWindow) tv_ItemActivated() {
msg := ``
for _, i := range mw.tv.SelectedIndexes() {
msg = msg + "\n" + mw.model.items[i].Name
}
walk.MsgBox(mw, "title", msg, walk.MsgBoxIconInformation)
}
效果:
文件选择器(加入了icon)
这里就是调用Windows的文件选择框
主要是使用:FileDialog
package main
import (
"github.com/lxn/walk"
. "github.com/lxn/walk/declarative"
)
import (
"fmt"
"os"
)
type MyMainWindow struct {
*walk.MainWindow
edit *walk.TextEdit
path string
}
func main() {
mw := &MyMainWindow{}
MW := MainWindow{
AssignTo: &mw.MainWindow,
Icon: "test.ico",
Title: "文件选择对话框",
MinSize: Size{150, 200},
Size: Size{300, 400},
Layout: VBox{},
Children: []Widget{
TextEdit{
AssignTo: &mw.edit,
},
PushButton{
Text: "打开",
OnClicked: mw.pbClicked,
},
},
}
if _, err := MW.Run(); err != nil {
fmt.Fprintln(os.Stderr, err)
os.Exit(1)
}
}
func (mw *MyMainWindow) pbClicked() {
dlg := new(walk.FileDialog)
dlg.FilePath = mw.path
dlg.Title = "Select File"
dlg.Filter = "Exe files (*.exe)|*.exe|All files (*.*)|*.*"
if ok, err := dlg.ShowOpen(mw); err != nil {
mw.edit.AppendText("Error : File Open\r\n")
return
} else if !ok {
mw.edit.AppendText("Cancel\r\n")
return
}
mw.path = dlg.FilePath
s := fmt.Sprintf("Select : %s\r\n", mw.path)
mw.edit.AppendText(s)
}
效果:
文本检索器
package main
import (
"fmt"
"log"
"strings"
"github.com/lxn/walk"
. "github.com/lxn/walk/declarative"
)
func main() {
mw := &MyMainWindow{}
if _, err := (MainWindow{
AssignTo: &mw.MainWindow,
Title: "SearchBox",
Icon: "test.ico",
MinSize: Size{300, 400},
Layout: VBox{},
Children: []Widget{
GroupBox{
Layout: HBox{},
Children: []Widget{
LineEdit{
AssignTo: &mw.searchBox,
},
PushButton{
Text: "检索",
OnClicked: mw.clicked,
},
},
},
TextEdit{
AssignTo: &mw.textArea,
},
ListBox{
AssignTo: &mw.results,
Row: 5,
},
},
}.Run()); err != nil {
log.Fatal(err)
}
}
type MyMainWindow struct {
*walk.MainWindow
searchBox *walk.LineEdit
textArea *walk.TextEdit
results *walk.ListBox
}
func (mw *MyMainWindow) clicked() {
word := mw.searchBox.Text()
text := mw.textArea.Text()
model := []string{}
for _, i := range search(text, word) {
model = append(model, fmt.Sprintf("%d检索成功", i))
}
log.Print(model)
mw.results.SetModel(model)
}
func search(text, word string) (result []int) {
result = []int{}
i := 0
for j, _ := range text {
if strings.HasPrefix(text[j:], word) {
log.Print(i)
result = append(result, i)
}
i += 1
}
return
}
效果:
邮件群发器
别人写的邮件群发器,出自:
https://studygolang.com/articles/2078
关于golang中stmp的使用,请看博客:
Go实战–通过net/smtp发送邮件(The way to go)
package main
import (
"bufio"
"encoding/gob"
"errors"
"fmt"
"io"
"net/smtp"
"os"
"strconv"
"strings"
"time"
)
import (
"github.com/lxn/walk"
. "github.com/lxn/walk/declarative"
)
type ShuJu struct {
Name string
Pwd string
Host string
Subject string
Body string
Send string
}
func SendMail(user, password, host, to, subject, body, mailtype string) error {
fmt.Println("Send to " + to)
hp := strings.Split(host, ":")
auth := smtp.PlainAuth("", user, password, hp[0])
var content_type string
if mailtype == "html" {
content_type = "Content-Type: text/html;charset=UTF-8"
} else {
content_type = "Content-Type: text/plain;charset=UTF-8"
}
body = strings.TrimSpace(body)
msg := []byte("To: " + to + "\r\nFrom: " + user + "<" + user + ">\r\nSubject: " + subject + "\r\n" + content_type + "\r\n\r\n" + body)
send_to := strings.Split(to, ";")
err := smtp.SendMail(host, auth, user, send_to, msg)
if err != nil {
fmt.Println(err.Error())
}
return err
}
func readLine2Array(filename string) ([]string, error) {
result := make([]string, 0)
file, err := os.Open(filename)
if err != nil {
return result, errors.New("Open file failed.")
}
defer file.Close()
bf := bufio.NewReader(file)
for {
line, isPrefix, err1 := bf.ReadLine()
if err1 != nil {
if err1 != io.EOF {
return result, errors.New("ReadLine no finish")
}
break
}
if isPrefix {
return result, errors.New("Line is too long")
}
str := string(line)
result = append(result, str)
}
return result, nil
}
func DelArrayVar(arr []string, str string) []string {
str = strings.TrimSpace(str)
for i, v := range arr {
v = strings.TrimSpace(v)
if v == str {
if i == len(arr) {
return arr[0 : i-1]
}
if i == 0 {
return arr[1:len(arr)]
}
a1 := arr[0:i]
a2 := arr[i+1 : len(arr)]
return append(a1, a2...)
}
}
return arr
}
func LoadData() {
fmt.Println("LoadData")
file, err := os.Open("data.dat")
defer file.Close()
if err != nil {
fmt.Println(err.Error())
SJ.Name = "用户名"
SJ.Pwd = "用户密码"
SJ.Host = "SMTP服务器:端口"
SJ.Subject = "邮件主题"
SJ.Body = "邮件内容"
SJ.Send = "要发送的邮箱,每行一个"
return
}
dec := gob.NewDecoder(file)
err2 := dec.Decode(&SJ)
if err2 != nil {
fmt.Println(err2.Error())
SJ.Name = "用户名"
SJ.Pwd = "用户密码"
SJ.Host = "SMTP服务器:端口"
SJ.Subject = "邮件主题"
SJ.Body = "邮件内容"
SJ.Send = "要发送的邮箱,每行一个"
}
}
func SaveData() {
fmt.Println("SaveData")
file, err := os.Create("data.dat")
defer file.Close()
if err != nil {
fmt.Println(err)
}
enc := gob.NewEncoder(file)
err2 := enc.Encode(SJ)
if err2 != nil {
fmt.Println(err2)
}
}
var SJ ShuJu
var runing bool
var chEnd chan bool
func main() {
LoadData()
chEnd = make(chan bool)
var emails, body, msgbox *walk.TextEdit
var user, password, host, subject *walk.LineEdit
var startBtn *walk.PushButton
MainWindow{
Title: "邮件发送器",
MinSize: Size{800, 600},
Layout: HBox{},
Children: []Widget{
TextEdit{AssignTo: &emails, Text: SJ.Send, ToolTipText: "待发送邮件列表,每行一个"},
VSplitter{
Children: []Widget{
LineEdit{AssignTo: &user, Text: SJ.Name, CueBanner: "请输入邮箱用户名"},
LineEdit{AssignTo: &password, Text: SJ.Pwd, PasswordMode: true, CueBanner: "请输入邮箱登录密码"},
LineEdit{AssignTo: &host, Text: SJ.Host, CueBanner: "SMTP服务器:端口"},
LineEdit{AssignTo: &subject, Text: SJ.Subject, CueBanner: "请输入邮件主题……"},
TextEdit{AssignTo: &body, Text: SJ.Body, ToolTipText: "请输入邮件内容", ColumnSpan: 2},
TextEdit{AssignTo: &msgbox, ReadOnly: true},
PushButton{
AssignTo: &startBtn,
Text: "开始群发",
OnClicked: func() {
SJ.Name = user.Text()
SJ.Pwd = password.Text()
SJ.Host = host.Text()
SJ.Subject = subject.Text()
SJ.Body = body.Text()
SJ.Send = emails.Text()
SaveData()
if runing == false {
runing = true
startBtn.SetText("停止发送")
go sendThread(msgbox, emails)
} else {
runing = false
startBtn.SetText("开始群发")
}
},
},
},
},
},
}.Run()
}
func sendThread(msgbox, es *walk.TextEdit) {
sendTo := strings.Split(SJ.Send, "\r\n")
susscess := 0
count := len(sendTo)
for index, to := range sendTo {
if runing == false {
break
}
msgbox.SetText("发送到" + to + "..." + strconv.Itoa((index/count)*100) + "%")
err := SendMail(SJ.Name, SJ.Pwd, SJ.Host, to, SJ.Subject, SJ.Body, "html")
if err != nil {
msgbox.AppendText("\r\n失败:" + err.Error() + "\r\n")
if err.Error() == "550 Mailbox not found or access denied" {
SJ.Send = strings.Join(DelArrayVar(strings.Split(SJ.Send, "\r\n"), to), "\r\n")
es.SetText(SJ.Send)
}
time.Sleep(1 * time.Second)
continue
} else {
susscess++
msgbox.AppendText("\r\n发送成功!")
SJ.Send = strings.Join(DelArrayVar(strings.Split(SJ.Send, "\r\n"), to), "\r\n")
es.SetText(SJ.Send)
}
time.Sleep(1 * time.Second)
}
SaveData()
msgbox.AppendText("停止发送!成功 " + strconv.Itoa(susscess) + " 条\r\n")
}
效果:
作者:wangshubo1989 发表于2017/9/12 20:23:57 原文链接
阅读:451 评论:0 查看评论
↧
MySql函数 - DATE_ADD()函数
MySql函数 - DATE_ADD()函数
1.函数用途
date_add() 函数用来对日期进行加减2.函数调用形式
// @date 欲操作的日期
// INTERVAL 关键字
// expr 日期加减的数值
// unit 日期加减的类型
DATE_ADD(date,INTERVAL expr unit)3.unit 支持的类型
MICROSECOND
SECOND
MINUTE
HOUR
DAY
WEEK
MONTH
QUARTER
YEAR
SECOND_MICROSECOND
MINUTE_MICROSECOND
MINUTE_SECOND
HOUR_MICROSECOND
HOUR_SECOND
HOUR_MINUTE
DAY_MICROSECOND
DAY_SECOND
DAY_MINUTE
DAY_HOUR
YEAR_MONTH
4.简单应用
// 得到当前时间增加1个小时的结果
select date_add(now(),interval 1 hour)
// 得到当前时间增加1天的结果
select date_add(now(),interval 1 day)
// 得到当前时间减少72个小时的结果
select date_add(now(),interval -72 hour)
// 还有一些更加高级的用法,比如增加一天一小时一分一秒
// 但是如果你不太喜欢这种用法,你仍然可以使用等同于该数值的second来进行加减
date_add(now(),interval '1 1:1:1' day_second)
作者:qq_15071263 发表于2017/9/12 20:30:30 原文链接
阅读:146 评论:0 查看评论
↧
MySql函数 - FIND_IN_SET函数
MySql函数 - FIND_IN_SET函数
1.函数简介
FIND_IN_SET函数 是一个比like关键字更加高级的精确查询匹配
2.调用形式
// 可以用Java中的set集合来理解,在一个set集合中查找某个值是否存在
find_in_set('欲查找的值','被查找的值的集合,用英文逗号分隔开')3.简单应用
// 以下查询将得到结果 2
// 当他包含在set集合里面时,返回在集合中的位置,下标从1开始
SELECT FIND_IN_SET('b','a,b,c,d')
// 当然,他还可以被应用到where子句中,比如下面这种形式
// 比如,某篇文章type是科技类,又是时事类,又是热点类,而你想找表中所有的科技类文章时,该方式可以得到应用
select xxx from xxx as s where 1=1 and find_in_set('some type',s.type)
作者:qq_15071263 发表于2017/9/12 20:56:02 原文链接
阅读:169 评论:0 查看评论
↧
NGUI_PopupList_012
↧
↧
Tracking the World State with Recurrent Entity Networks--阅读笔记和TensorFlow实现
这篇论文是facebook在前段时间ICLR会议上发表的论文,提出了一种Recurrent Entity Network的模型用来对world state进行建模,实时的根据模型的输入对记忆单元进行更新,从而得到对world的一个即时的认识。该模型可以用于机器阅读理解、QA等领域。下面对论文所提出的模型架构进行一个简单的概述:
1,论文提出了一种新的动态记忆网络,其使用固定长度的记忆单元来存储世界上的实体,每个记忆单元对应一个实体,主要存储该实体相关的属性(譬如一个人拿了什么东西,在哪里,跟谁等等信息),且该记忆会随着输入内容实时更新。
2,多个记忆单元(memory slot)之间相互独立,由(key,value)组成。key用来标识实体Entity,value用来存储实体相关的属性,也就是记忆。使用Gated RNN来实现该记忆单元的功能,也就是说每个memory slot都是一个单独的一层RNN,对于一个输入st会同时计算m个memory slot,其间相互独立。但是网络的参数相同。可以爸这多个memory slot类比成多层RNN,但是每一层的输入不是上一层的输出或者记忆,而是第一层的输入st。
其架构图如下图所示,方块代表memory cell,一层代表一个recurrent RNN,也就是一个memory slot,用来存储一个实体及其相关属性,共m层,且相互独立,但是每层内、各层间各个方块之间的参数共享,保持一致。key对应于w参数,每一层的w不一样,用来标识不同的实体。(w,h)就是记忆单元。我们可以看到:
我们先用一个简单的例子来通俗的介绍一下模型的工作原理。例如我们模型输入的是下面三句话,前面两句是模型要阅读的材料,最后一句话是问题。我们的模型目的就是根据材料和问题得到答案。
Mary picked up the ball.
Mary went to the garden.
Where is the ball?当模型读入第一句话时,模型会学习到mary和ball两个实体,假设第一个memory slot学习Mary,第二个学习ball,也就是说key w1会学习输入中的mary实体,而key w2会学习到ball实体。这也就是每个memory slot的key的意义,用来标识输入中的实体。那么记忆h是什么呢?第一个会学到mary拿着球,第二个会学到球被mary拿着。接下来读入第二句话,首先第一个memory slot会检测到mary,然后将其记忆更新为mary拿着球,在花园中;第二个虽然并未检测到ball这个实体,但是其memory中有关于mary的记忆,所以也会做出相应的更新(这部分可以参考下面的动态记忆模块),将记忆更新为球被mary拿着,在花园中。同样第三个memory slot会学习到花园这个实体,并将其记忆更新为mary和球都在其中。当读入问题的时候,会先学习到ball这个实体,然后将其跟m个memory slot做Attention,也就是求问题跟m个slot之间的关系,显然第二个实体的重要性更大。然后将m个slot的记忆进行加权得到我们的输出答案。这就是模型的工作流程。主要体现在动态记忆 实时更新 Tracking the World State
下面分别介绍一下模型的三个主要组件,输入模块、动态记忆模块、输出模块。
输入模块
我们的输入是batch_size*story_len*sent_len*embed_size的四维tensor story故事或者去掉story_len的query问题。那么输入层的主要作用是将sent_len这个维度去掉,也就是将句子中的所有单词进行加权得到一个句子的representation 向量。如下:
其中f是一个模型需要学习的变量,其将句子中的每个单词进行加权的到句子的向量表示,也就是Gated RNN记忆单元的输入。f用来学习句子的位置信息,我感觉这里最终f将学习到句子的主谓宾这种位置关系,因为模型需要学习出输入中的实体信息(个人理解)。反正最终通过f参数对句子当中的所有单词进行加权求和我们就能得到句子的向量表示。
动态记忆模块
同样是上面的框架图,这里我们进行详细的介绍:
对于每个memory slot j 而言,首先第一个公式,分别使用前一时刻的记忆 h 和该记忆单元的key w与输入s相乘然后经过激活函数得到一个门控单元g,这里w和h分别用于提取s中与本slot相关的实体信息和s与本slot实体属性相关的信息。对应上面那个例子,当输入第二句话时,w与s相乘,因为s中没有ball相关的信息,所以得0,但是h与s相乘时,因为h中有mary相关的信息,所以h与s相乘不等于零,最终仍然会对记忆进行更新。这里门控的概念大家可以仔细看一下架构图,四个单元每个单元门控的符号的方向是不一样的,也就暗示了g的取值会导致h的更新幅度。
第二个公式就是传统的RNN单元,用于计算当输入s时,需要更新的内容,需要注意的是UVW这三个参数在所有的记忆单元当中都是共享的。第三个公式则是根据门控单元g和h来对记忆进行更新,将新的信息写入记忆之中(第二句改成mary拿着球到了花园)。第四个公式是对新的记忆进行归一化,论文中提到该归一化可以达到忘记门的作用(比如说第三句话是mary went bedroom,那么记忆就会忘记mary在花园这个信息),但是这里我不是很明白为什么对记忆进行归一化操作的时候可以实现忘记的功能。这里按照论文中给出的解释梳理一下,如下图,原本的记忆是归一化的在单位域内,然后经过门控之后的新的记忆是上面那个向量,所以二者的和(公式3)是一个比较长的向量,然后将其归一化到单位域内,可以理解为其幅度变小了。接下来有两种理解方式:
- 数值被归一化,则表明其可以编码的信息量变小。
- 幅度变小后,在后面的更新过程中与别的变量相乘或者别的什么操作时,对该变量的影响变小,间接起到忘记的效果
但是这两种想法都是我自己强行靠结论得到的,还希望如果有谁明白其中的数学道理可以解释一下。
输出模块
经过动态记忆模块,我们已经把输入转化为memory存储在各个memory slot里面,那么接下来的工作就是根据Query来产生该问题的答案。第一步要将Query编码成一个向量,使用与输入模块相同的操作去编码问题中的实体(例如上栗中的ball),然后使用第一个等式将Query 的向量表示与每个memory slot相乘在经过softmax,这就相当于是一层Attention,用于获得Query与每个slot之间的相关程度,上例中Query会与第二个slot(ball)最相关,与其他slot相关度较小。然后使用该Attention之后的p作为每个slot的权重进行加权得到memory中关于该Query的相关记忆,作为答案候选。接下来进过一个简单的输出层将其编码为最终的答案即可。文中提到,这个输出层与一个one-hop的memory network相似,这里我还不是很清楚one-hop的概念==
这样,经过上面三个模块,我们就得到了最终的模型,也就是根据输入的story和Query我们可以得到该问题的答案。下面要做的就是根据训练数据train我们的模型,一步步迭代更新即可。
TensorFlow实现
因为该论文发表出来之后github上面就已经有了比较成熟的实现方案,我也就不在自己去实现,这里参考https://github.com/siddk/entity-network的代码进行简单的介绍。
其实前面实现了这么多论文的仿真,我们也可以看出基本上工作量就在数据处理和模型构建两部分,模型的训练部分代码基本上都是重复性操作,所以我们这里主要看一下其模型构建部分的代码。
由于该模型提出的Gated RNN模型在TensorFlow中并未有现成的实现方案,所以我们需要定义自己的RNN Cell,这也是我第一次去看RNN Cell的源码,其实发现定义自己的RNN模型也是很简单的,只需要继承tf.contrib.rnn.RNNCell类,然后重新定义其call函数即可。先来看一下自定义的DynamicMemory类程序,主要是实现上面动态记忆模块部分的四个公式:
class DynamicMemory(tf.contrib.rnn.RNNCell):
def __init__(self, memory_slots, memory_size, keys, activation=prelu,
initializer=tf.random_normal_initializer(stddev=0.1)):
"""
Instantiate a DynamicMemory Cell, with the given number of memory slots, and key vectors.
:param memory_slots: Number of memory slots to initialize.
:param memory_size: Dimensionality of memories => tied to embedding size.
:param keys: List of keys to seed the Dynamic Memory with (can be random).
:param initializer: Variable Initializer for Cell Parameters.
"""
self.m, self.mem_sz, self.keys = memory_slots, memory_size, keys
self.activation, self.init = activation, initializer
# 公式2中的三个参数,在所有RNN Cell中共享。
self.U = tf.get_variable("U", [self.mem_sz, self.mem_sz], initializer=self.init)
self.V = tf.get_variable("V", [self.mem_sz, self.mem_sz], initializer=self.init)
self.W = tf.get_variable("W", [self.mem_sz, self.mem_sz], initializer=self.init)
@property
def state_size(self):
return [self.mem_sz for _ in range(self.m)]
@property
def output_size(self):
return [self.mem_sz for _ in range(self.m)]
def zero_state(self, batch_size, dtype):
return [tf.tile(tf.expand_dims(key, 0), [batch_size, 1]) for key in self.keys]
def __call__(self, inputs, state, scope=None):
"""
Run the Dynamic Memory Cell on the inputs, updating the memories with each new time step.
:param inputs: 2D Tensor of shape [bsz, mem_sz] representing a story sentence.
:param states: List of length M, each with 2D Tensor [bsz, mem_sz] => h_j (starts as key).
"""
new_states = []
#下面的循环表示m个memory slot,对每个slot都执行相同的操作
for block_id, h in enumerate(state):
# 下面三行主要实现公式1,即门函数g的计算
content_g = tf.reduce_sum(tf.multiply(inputs, h), axis=[1]) # Shape: [bsz]
address_g = tf.reduce_sum(tf.multiply(inputs,
tf.expand_dims(self.keys[block_id], 0)), axis=[1]) # Shape: [bsz]
g = sigmoid(content_g + address_g)
#下面四行主要是公式2的计算,根据输入s和记忆h得到新的记忆h_
h_component = tf.matmul(h, self.U) # Shape: [bsz, mem_sz]
w_component = tf.matmul(tf.expand_dims(self.keys[block_id], 0), self.V) # Shape: [1, mem_sz]
s_component = tf.matmul(inputs, self.W) # Shape: [bsz, mem_sz]
candidate = self.activation(h_component + w_component + s_component) # Shape: [bsz, mem_sz]
# 将新的记忆h_与门空函数g相乘之后的结果加到原始的记忆h中
new_h = h + tf.multiply(tf.expand_dims(g, -1), candidate) # Shape: [bsz, mem_sz]
#对记忆h进行归一化
new_h_norm = tf.nn.l2_normalize(new_h, -1) # Shape: [bsz, mem_sz]
new_states.append(new_h_norm)
return new_states, new_states看完上面的代码其实我们就完成了memory cell的重定义,接下来我们就可以像使用普通的RNN、GRU、LSTM一样将其当做一个RNN cell传入dynamic_rnn函数中即可。然后我们看一下其模型的搭建过程,其实相当简单,就是按照上面三个模块走一遍即可,代码如下所示:
class EntityNetwork():
def __init__(self, vocabulary, sentence_len, story_len, batch_size, memory_slots, embedding_size,
learning_rate, decay_steps, decay_rate, clip_gradients=40.0,
initializer=tf.random_normal_initializer(stddev=0.1)):
"""
Initialize an Entity Network with the necessary hyperparameters.
:param vocabulary: Word Vocabulary for given model.
:param sentence_len: Maximum length of a sentence.
:param story_len: Maximum length of a story.
"""
self.vocab_sz, self.sentence_len, self.story_len = len(vocabulary), sentence_len, story_len
self.embed_sz, self.memory_slots, self.init = embedding_size, memory_slots, initializer
self.bsz, self.lr, self.decay_steps, self.decay_rate = batch_size, learning_rate, decay_steps, decay_rate
self.clip_gradients = clip_gradients
# Setup Placeholders
self.S = tf.placeholder(tf.int32, [None, self.story_len, self.sentence_len], name="Story")
self.S_len = tf.placeholder(tf.int32, [None], name="Story_Length")
self.Q = tf.placeholder(tf.int32, [None, self.sentence_len], name="Query")
self.A = tf.placeholder(tf.int64, [None], name="Answer")
# Setup Global, Epoch Step
self.global_step = tf.Variable(0, trainable=False, name="Global_Step")
self.epoch_step = tf.Variable(0, trainable=False, name="Epoch_Step")
self.epoch_increment = tf.assign(self.epoch_step, tf.add(self.epoch_step, tf.constant(1)))
# Instantiate Network Weights
self.instantiate_weights()
# Build Inference Pipeline
self.logits = self.inference()
# Build Loss Computation
self.loss_val = self.loss()
# Build Training Operation
self.train_op = self.train()
# Create operations for computing the accuracy
correct_prediction = tf.equal(tf.argmax(self.logits, 1), self.A)
self.accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32), name="Accuracy")
def instantiate_weights(self):
"""
Instantiate Network Weights, including all weights for the Input Encoder, Dynamic
Memory Cell, as well as Output Decoder.
"""
# Create Embedding Matrix, with 0 Vector for PAD_ID (0)
E = tf.get_variable("Embedding", [self.vocab_sz, self.embed_sz], initializer=self.init)
zero_mask = tf.constant([0 if i == 0 else 1 for i in range(self.vocab_sz)],
dtype=tf.float32, shape=[self.vocab_sz, 1])
self.E = E * zero_mask
# Create Learnable Mask
self.story_mask = tf.get_variable("Story_Mask", [self.sentence_len, 1], initializer=tf.constant_initializer(1.0))
self.query_mask = tf.get_variable("Query_Mask", [self.sentence_len, 1], initializer=tf.constant_initializer(1.0))
# Create Memory Cell Keys [IF DESIRED - TIE KEYS HERE]
self.keys = [tf.get_variable("Key_%d" % i, [self.embed_sz], initializer=self.init)
for i in range(self.memory_slots)]
# Create Memory Cell
self.cell = DynamicMemory(self.memory_slots, self.embed_sz, self.keys)
# Output Module Variables
self.H = tf.get_variable("H", [self.embed_sz, self.embed_sz], initializer=self.init)
self.R = tf.get_variable("R", [self.embed_sz, self.vocab_sz], initializer=self.init)
def inference(self):
"""
Build inference pipeline, going from the story and question, through the memory cells, to the
distribution over possible answers.
"""
# Story Input Encoder
story_embeddings = tf.nn.embedding_lookup(self.E, self.S) # Shape: [None, story_len, sent_len, embed_sz]
story_embeddings = tf.multiply(story_embeddings, self.story_mask) # Shape: [None, story_len, sent_len, embed_sz]
story_embeddings = tf.reduce_sum(story_embeddings, axis=[2]) # Shape: [None, story_len, embed_sz]
# Query Input Encoder
query_embedding = tf.nn.embedding_lookup(self.E, self.Q) # Shape: [None, sent_len, embed_sz]
query_embedding = tf.multiply(query_embedding, self.query_mask) # Shape: [None, sent_len, embed_sz]
query_embedding = tf.reduce_sum(query_embedding, axis=[1]) # Shape: [None, embed_sz]
# Send Story through Memory Cell
initial_state = self.cell.zero_state(self.bsz, dtype=tf.float32)
_, memories = tf.nn.dynamic_rnn(self.cell, story_embeddings, sequence_length=self.S_len,
initial_state=initial_state)
# Output Module
stacked_memories = tf.stack(memories, axis=1)
# Generate Memory Scores
p_scores = softmax(tf.reduce_sum(tf.multiply(stacked_memories, # Shape: [None, mem_slots]
tf.expand_dims(query_embedding, 1)), axis=[2]))
# Subtract max for numerical stability (softmax is shift invariant)
p_max = tf.reduce_max(p_scores, axis=-1, keep_dims=True)
attention = tf.nn.softmax(p_scores - p_max)
attention = tf.expand_dims(attention, 2) # Shape: [None, mem_slots, 1]
# Weight memories by attention vectors
u = tf.reduce_sum(tf.multiply(stacked_memories, attention), axis=1) # Shape: [None, embed_sz]
# Output Transformations => Logits
hidden = prelu(tf.matmul(u, self.H) + query_embedding) # Shape: [None, embed_sz]
logits = tf.matmul(hidden, self.R) # Shape: [None, vocab_sz]
return logits
def loss(self):
"""
Build loss computation - softmax cross-entropy between logits, and correct answer.
"""
return tf.losses.sparse_softmax_cross_entropy(self.A, self.logits)
def train(self):
"""
Build ADAM Optimizer Training Operation.
"""
learning_rate = tf.train.exponential_decay(self.lr, self.global_step, self.decay_steps,
self.decay_rate, staircase=True)
train_op = tf.contrib.layers.optimize_loss(self.loss_val, global_step=self.global_step,
learning_rate=learning_rate, optimizer="Adam",
clip_gradients=self.clip_gradients)
return train_op主要是instantiate_weights和inference两个函数,分别起到变量参数的定义以及模型搭建。感兴趣的同学可以自己看一下。
最后为了方便我们查看我们搭建好的模型,所以我对源码进行了一定的修改,主要是添加了一下graph的构建模块,这样就可以很方便的在tensorboard上面查看。其次由于训练时间较长,所以并未执行训练过程,这里就贴一个graph图来展示一下==
几个问题
最后呢,我也把论文中的几个自己不是很明白的地方整理了一下,
1,如果要编码world-state,那应该会有很多个实体,但模型中只用了m个记忆块。如何对应?
- 这里我也有两种想法,第一个是经过观察训练数据,其实里面所涉及到的实体很少,基本少20个slot足以,所以这里仅用m个slot来学习世界的状态。第二个就是CBT数据集很明显实体量会变大很多,那么如何学习所有的实体呢??或许是模型会每次训练都学习该数据中的?但是也有点数不同的样子==所以这个问题也希望有明白的同学可以指点一二
2,模型不同的memory之间的关系是什么,与多层RNN的区别。
- 这里不同的memory slot之间是相互独立的,通过wj来决定输入的不同内容应该激活哪个memory slot。且其输入都是st和上一时间点的记忆。而多层RNN,下一层的输入是上一层的输出。有着本质的区别。我觉的这里wj起到了关键作用,因为如果没有该向量的话,m个slot就是完全独立的记忆,不会产生什么区别,而wj却起到了区分的作用。
3,为什么对记忆归一化可以忘去过去的信息?
- 原始记忆在单位领域内,当添加新信息的时候会减小二者之间的余弦距离,得到新的记忆。再进行归一化到单位向量时,会逐渐忘记以前的记忆。具体的解释见上文
作者:liuchonge 发表于2017/9/12 21:08:32 原文链接
阅读:148 评论:0 查看评论
↧
POJ 1269 Intersecting Lines
传送门:点击打开链接
Intersecting Lines
| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 16736 | Accepted: 7213 |
Description
We all know that a pair of distinct points on a plane defines a line and that a pair of lines on a plane will intersect in one of three ways: 1) no intersection because they are parallel, 2) intersect in a line because they are on top of one another (i.e. they
are the same line), 3) intersect in a point. In this problem you will use your algebraic knowledge to create a program that determines how and where two lines intersect.
Your program will repeatedly read in four points that define two lines in the x-y plane and determine how and where the lines intersect. All numbers required by this problem will be reasonable, say between -1000 and 1000.
Your program will repeatedly read in four points that define two lines in the x-y plane and determine how and where the lines intersect. All numbers required by this problem will be reasonable, say between -1000 and 1000.
Input
The first line contains an integer N between 1 and 10 describing how many pairs of lines are represented. The next N lines will each contain eight integers. These integers represent the coordinates of four points on the plane in the order x1y1x2y2x3y3x4y4.
Thus each of these input lines represents two lines on the plane: the line through (x1,y1) and (x2,y2) and the line through (x3,y3) and (x4,y4). The point (x1,y1) is always distinct from (x2,y2). Likewise with (x3,y3) and (x4,y4).
Output
There should be N+2 lines of output. The first line of output should read INTERSECTING LINES OUTPUT. There will then be one line of output for each pair of planar lines represented by a line of input, describing how the lines intersect: none, line, or point.
If the intersection is a point then your program should output the x and y coordinates of the point, correct to two decimal places. The final line of output should read "END OF OUTPUT".
Sample Input
5 0 0 4 4 0 4 4 0 5 0 7 6 1 0 2 3 5 0 7 6 3 -6 4 -3 2 0 2 27 1 5 18 5 0 3 4 0 1 2 2 5
Sample Output
INTERSECTING LINES OUTPUT POINT 2.00 2.00 NONE LINE POINT 2.00 5.00 POINT 1.07 2.20 END OF OUTPUT
Source
题意就是给你四个点,每两点确定一条直线,问两直线是否有交点,有交点输出,没有输出共线或平行。
关键在于判断斜率,因为有斜率不存在的情况,如果是单独求k的话,斜率不存在还要单独拿出来考虑,第一次就没判断k,各种WA。然后可以利用向量的叉乘,若叉乘为0代表两直线平行,再去判断是否共线,这样成功避开了k的取值。最后得到正确结果还是花样WA,竟然是因为G++的问题,看了一眼讨论版才知道,可怕啊。
代码实现:
#include<iostream>
#include<algorithm>
#include<cstring>
#include<cmath>
#include<queue>
#include<cstdio>
#define ll int
#define mset(a,x) memset(a,x,sizeof(a))
using namespace std;
const double PI=acos(-1);
const int inf=0x3f3f3f3f;
const double eps=1e-8;
const int maxn=5e5+5;
const int mod=1e9+7;
int dir[4][2]={0,1,1,0,0,-1,-1,0};
struct point{
double x,y;
point(){};
point(double newx,double newy)
{
x=newx;y=newy;
}
point operator -(const point &b)
{
return point(x-b.x,y-b.y);
}
};
struct line{
point a,b;
};
int across(line p,line q)
{
point tempa=(p.b-p.a);
point tempb=(q.b-q.a);
if(tempa.x*tempb.y-tempb.x*tempa.y==0)
return 0;
else
return 1;
}
int main()
{
int n,i,j,k;
line a,b;
cin>>n;
cout<<"INTERSECTING LINES OUTPUT"<<endl;
while(n--)
{
cin>>a.a.x>>a.a.y>>a.b.x>>a.b.y>>b.a.x>>b.a.y>>b.b.x>>b.b.y;
if(!across(a,b)) //平行
{
double b1=a.a.y-a.a.x*((a.b.y-a.a.y)/(a.b.x-a.a.x));
double b2=b.a.y-b.a.x*((b.b.y-b.a.y)/(b.b.x-b.a.x));
if(b1==b2)
cout<<"LINE"<<endl;
else
cout<<"NONE"<<endl;
}
else //相交
{
double a1,a2,b1,b2,c1,c2,x,y;
a1=a.b.x-a.a.x;a2=b.b.x-b.a.x;
b1=a.a.y-a.b.y;b2=b.a.y-b.b.y;
c1=a.a.x*a.b.y-a.a.y*a.b.x;
c2=b.a.x*b.b.y-b.a.y*b.b.x;
x=(c1*a2-c2*a1)/(a1*b2-a2*b1);
y=(c1*b2-c2*b1)/(a2*b1-a1*b2);
printf("POINT %.2lf %.2lf\n",x,y);
}
}
cout<<"END OF OUTPUT"<<endl;
return 0;
}
作者:Ever_glow 发表于2017/9/12 21:10:45 原文链接
阅读:171 评论:0 查看评论
↧
MultiDex
1. 前言
最近做项目开发的时候,遇到一个问题,NoClassDef,NoMethod之类的错误,但是把log往前看,会发现一些Dalvik的一些报错,看到这些log之后,就会觉得后面的什么方法找不到,类没有定义什么的错误真是的应该出现,那么这些Dalvik的错误怎么解释呢?
因为类似的报错只出现在了一个同事的手机上,而且是KK版本,比较老。介绍下我的分析思路:
1. 确定问题发生位置,注释掉(并解决因注释引起的编译错误)—> Defeat
2. 因为是KK版本,调整minSDK到19 —> Defeat
3. 删除或者更新引起问题的jar包 —> Defeat
4. 考虑到MultiDex在Android5.0 以后默认支持,为兼容旧版本,手动兼容一下
————————>Victory
2. 配置MultiDex
Android5.0及以上版本默认支持MultiDex
2.1 修改build.gradle
android {
compileSdkVersion 21
buildToolsVersion "21.1.0"
defaultConfig {
...
minSdkVersion 14
targetSdkVersion 21
...
// Enabling MultiDex support.
multiDexEnabled true
}
...
}
dependencies { compile 'com.android.support:multidex:1.0.1'
}2.2 修改application
三种方法
2.2.1 在AndroidManifest.xml的application中声明android.support.MultiDex.MultiDexApplication
2.2.2 让自己的application类继承MultiDexApplication;
2.2.3 重写attachBaseContext()方法
@Override
protected void attachBaseContext(Context base) {
super.attachBaseContext(base);
MultiDex.install(this);
}3. 推荐文章
更多关于MultiDex可以查阅
美团技术沙龙关于分包的博客
或者直接查看MultiDex源码。
作者:poorkick 发表于2017/9/12 21:23:09 原文链接
阅读:164 评论:0 查看评论
↧
差分约束系统的学习 poj1364(bellman和spfa)
差分约束系统
【概念】:对于一个序列。
给出m个不等式,形如a+b<=k
问,同时满足这m个不等式的解存不存在。
推荐讲解:http://www.cppblog.com/menjitianya/archive/2015/11/19/212292.html
【学习】:
我是通过一个三角不等式看懂的。
如下三个不等式:(摘自上述博客)
B - A <= c (1)
C - B <= a (2)
C - A <= b (3)
我们想要知道C - A的最大值,通过(1) + (2),可以得到 C - A <= a + c,所以这个问题其实就是求min{b, a+c}。将上面的三个不等式按照 三-1
数形结合 中提到的方式建图,如图三-2-1所示。

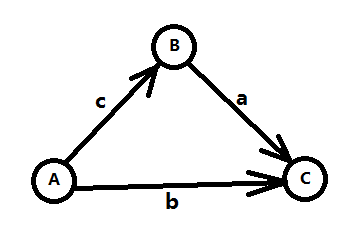
图三-2-1
我们发现min{b, a+c}正好对应了A到C的最短路,而这三个不等式就是著名的三角不等式。将三个不等式推广到m个,变量推广到n个,就变成了n个点m条边的最短路问题了。
不管题目给出的不等式是 > , < ,>=,我们都可以通过移项等操作统一为<=
然后可以用最短路的思想(结合这个三角不等式理解),对这m个不等式做一个收缩操作
即求一条最短路,比如求的0->n的最短路为len,恢复成X0 - Xn <= len;
这条最短路如果求得出来,那么这个序列就是存在的。
什么时候求不出来呢?
建成的有向图是存在负环的时候。这是因为有几个不等式是相互矛盾的,比方x-y>0和x-y<0。不可能同时成立
这时用bellman算法可以直接判环。
或者是spfa计算每个点的遍历次数,某个点的次数>n则存在负环
为什么存在负环?
比方x-y>5和x-y<3(相矛盾),统一一下符号就是:y-x<= -6 , x-y<=2
这样建图就是x->y=2,y->x=-6
很明显这是一个负环!也就是只要存在相矛盾的不等式,一定会构成负环,你找不出反例
当存在负环时,最短路算法计算过程中会不断将路长变小(因为负数越加越小,相当于减法)
所以用spfa或bellman判环就是核心。
【例题】poj1364
King点击打开链接
| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 13843 | Accepted: 4920 |
Description
Once, in one kingdom, there was a queen and that queen was expecting a baby. The queen prayed: ``If my child was a son and if only he was a sound king.''
After nine months her child was born, and indeed, she gave birth to a nice son.
Unfortunately, as it used to happen in royal families, the son was a little retarded. After many years of study he was able just to add integer numbers and to compare whether the result is greater or less than a given integer number. In addition, the numbers had to be written in a sequence and he was able to sum just continuous subsequences of the sequence.
The old king was very unhappy of his son. But he was ready to make everything to enable his son to govern the kingdom after his death. With regards to his son's skills he decided that every problem the king had to decide about had to be presented in a form of a finite sequence of integer numbers and the decision about it would be done by stating an integer constraint (i.e. an upper or lower limit) for the sum of that sequence. In this way there was at least some hope that his son would be able to make some decisions.
After the old king died, the young king began to reign. But very soon, a lot of people became very unsatisfied with his decisions and decided to dethrone him. They tried to do it by proving that his decisions were wrong.
Therefore some conspirators presented to the young king a set of problems that he had to decide about. The set of problems was in the form of subsequences Si = {aSi, aSi+1, ..., aSi+ni} of a sequence S = {a1, a2, ..., an}. The king thought a minute and then decided, i.e. he set for the sum aSi + aSi+1 + ... + aSi+ni of each subsequence Si an integer constraint ki (i.e. aSi + aSi+1 + ... + aSi+ni < ki or aSi + aSi+1 + ... + aSi+ni > ki resp.) and declared these constraints as his decisions.
After a while he realized that some of his decisions were wrong. He could not revoke the declared constraints but trying to save himself he decided to fake the sequence that he was given. He ordered to his advisors to find such a sequence S that would satisfy the constraints he set. Help the advisors of the king and write a program that decides whether such a sequence exists or not.
Unfortunately, as it used to happen in royal families, the son was a little retarded. After many years of study he was able just to add integer numbers and to compare whether the result is greater or less than a given integer number. In addition, the numbers had to be written in a sequence and he was able to sum just continuous subsequences of the sequence.
The old king was very unhappy of his son. But he was ready to make everything to enable his son to govern the kingdom after his death. With regards to his son's skills he decided that every problem the king had to decide about had to be presented in a form of a finite sequence of integer numbers and the decision about it would be done by stating an integer constraint (i.e. an upper or lower limit) for the sum of that sequence. In this way there was at least some hope that his son would be able to make some decisions.
After the old king died, the young king began to reign. But very soon, a lot of people became very unsatisfied with his decisions and decided to dethrone him. They tried to do it by proving that his decisions were wrong.
Therefore some conspirators presented to the young king a set of problems that he had to decide about. The set of problems was in the form of subsequences Si = {aSi, aSi+1, ..., aSi+ni} of a sequence S = {a1, a2, ..., an}. The king thought a minute and then decided, i.e. he set for the sum aSi + aSi+1 + ... + aSi+ni of each subsequence Si an integer constraint ki (i.e. aSi + aSi+1 + ... + aSi+ni < ki or aSi + aSi+1 + ... + aSi+ni > ki resp.) and declared these constraints as his decisions.
After a while he realized that some of his decisions were wrong. He could not revoke the declared constraints but trying to save himself he decided to fake the sequence that he was given. He ordered to his advisors to find such a sequence S that would satisfy the constraints he set. Help the advisors of the king and write a program that decides whether such a sequence exists or not.
Input
The input consists of blocks of lines. Each block except the last corresponds to one set of problems and king's decisions about them. In the first line
of the block there are integers n, and m where 0 < n <= 100 is length of the sequence S and 0 < m <= 100 is the number of subsequences Si. Next m lines contain particular decisions coded in the form of quadruples si, ni, oi, ki, where oi represents operator
> (coded as gt) or operator < (coded as lt) respectively. The symbols si, ni and ki have the meaning described above. The last block consists of just one line containing 0.
Output
The output contains the lines corresponding to the blocks in the input. A line contains text successful conspiracy when such a sequence does not exist.
Otherwise it contains text lamentable kingdom. There is no line in the output corresponding to the last ``null'' block of the input.
Sample Input
4 2
1 2 gt 0
2 2 lt 2
1 2
1 0 gt 0
1 0 lt 0
0
Sample Output
lamentable kingdom
successful conspiracy
【题意】:
问是否存在一个n元素的序列满足输入的不等式。但是这里比较的是子段和。
比如输入的第二行 2 2 lt 2 ,表示从第2项起,连续的2项之和 小于 2
【解析】:
将输入的不等式统一为<=的形式,并建有向图。然后判负环。
两种代码理论上都需要建一个超级源点,指向所有点,且权值为0。
理由:作为最短路起点,权值为0不影响判环
但是会在一次遍历过后使得所有的最短路均为0、
然后n次遍历后还会继续被更新缩小,只能说明存在负环,越负越小。
若不存在负环,dis数组始终为0
bellman写法中可以省略超级源点,直接将dis数组清为0即可。
那么如果存在负环,权值为0的最短路照样会被更新,而达到判环的目的(仅限判环,求最短路不能这么玩)
而在spfa中这个超级源点的作用也就仅仅是给spfa一个头结点作为bfs的开始。
一次遍历之后dis必然全为0。判环原理同bellman
总之所谓的判环,一定就是不断缩小最短路以至于无限缩小。只要在n次之后终结即可
【代码】bellman和spfa(后者效率高)
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
#include<queue>
using namespace std;
struct node{
int u,to,len,next;
}e[10101];
int head[101];
int n,m,cnt;
int dis[102];
int in[102];//记录入度
void add(int u,int v,int len)
{
e[cnt]=(node){u,v,len,head[u]};
head[u]=cnt++;
}
int bellman()
{
memset(dis,0,sizeof(dis));
//收缩操作
for(int i=0;i<=n;i++)
for(int j=0;j<cnt;j++)
if(dis[e[j].to]>dis[e[j].u]+e[j].len)
dis[e[j].to]=dis[e[j].u]+e[j].len;
for(int j=0;j<cnt;j++)
if(dis[e[j].to]>dis[e[j].u]+e[j].len)
return 0;
return 1;
}
int main()
{
while(scanf("%d",&n),n)
{
scanf("%d",&m);
memset(in,0,sizeof(in));
memset(head,-1,sizeof(head));
cnt=0;
while(m--)
{
int u,len,k; char s[9];
scanf("%d%d%s%d",&u,&len,s,&k);//sum(au~au+len)
if(s[0]=='g')//>要转<=
add(u+len,u-1,-k-1);
else
add(u-1,u+len,k-1);
}
int ans=bellman();
if(ans)puts("lamentable kingdom");
else puts("successful conspiracy");
}
}
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
#include<queue>
using namespace std;
struct node{
int u,to,len,next;
}e[10101];
int head[101];
int n,m,cnt;
int dis[102];
int in[102];//记录入度
void add(int u,int v,int len)
{
e[cnt]=(node){u,v,len,head[u]};
head[u]=cnt++;
}
int spfa(int s)
{
memset(dis,0x3f,sizeof(dis));
memset(in,0,sizeof(in));
queue<int>q;
q.push(s);
dis[s]=0;
while(!q.empty())
{
int u=q.front();q.pop();
for(int i=head[u];~i;i=e[i].next)
{
int v=e[i].to;
if(dis[v]>dis[u]+e[i].len)
{
dis[v]=dis[u]+e[i].len;
q.push(v);
in[v]++;
if(in[v]>n+1)return 0;
}
}
}
return 1;
}
int main()
{
while(scanf("%d",&n),n)
{
scanf("%d",&m);
memset(in,0,sizeof(in));
memset(head,-1,sizeof(head));
cnt=0;
while(m--)
{
int u,len,k; char s[9];
scanf("%d%d%s%d",&u,&len,s,&k);//sum(au~au+len)
if(s[0]=='g')//>要转<=
add(u+len,u-1,-k-1);
else
add(u-1,u+len,k-1);
}
//建超级源点
for(int i=0;i<=n;i++)//注意前面建的图实际上有n+1个点
add(n+2,i,0);
int ans=spfa(n+2);
if(ans)puts("lamentable kingdom");
else puts("successful conspiracy");
}
}
作者:winter2121 发表于2017/9/12 21:52:59 原文链接
阅读:166 评论:0 查看评论
↧
↧
NGUI_CheckBox_013
↧
单体内置对象——ECMAScript
简介
内置对象:“由 ECMAScript 实现提供的、不依赖于宿主环境的对象,这些对象在 ECMAScript 程序执行之前就已经存在了,例如Object、Array 和 String
Global对象
属性
1、不属于任何其他对象的属性和方法,最终都是它的属性和方法
2、所有在全局作用域中定义的属性和函数,都是 Global 对象的属性
3、Global 对象还包含一些属性,例如特殊的值 undefined、NaN 以及 Infinity 都是 Global 对象的属性。此外,所有原生引用类型的构造函数,像 Object 和 Function,也都是 Global 对象的属性
URI编码方法
encodeURI()和 encodeURIComponent()
作用
对 URI(Uniform Resource Identifiers,通用资源标识符)进行编码,以便发送给浏览器。有效的 URI 中不能包含某些字符,例如空格。而这两个 URI 编码方法就可以对 URI 进行编码,它们用特殊的 UTF-8 编码替换所有无效的字符, 从而让浏览器能够接受和理解
主要区别
1、encodeURI()主要用于整个 URI(例如,http://www.wrox.com/illegal value.htm),而 encode- URIComponent()主要用于对 URI 中的某一段(例如前面 URI 中的 illegal value.htm)进行编码
2、encodeURI()不会对本身属于 URI 的特殊字符进行编码,例如冒号、正斜杠、 问号和井字号;而 encodeURIComponent()则会对它发现的任何非标准字符进行编码
例如:
var uri = "http://www.wrox.com/illegal value.htm#start";
//"http://www.wrox.com/illegal%20value.htm#start" alert(encodeURI(uri));
//"http%3A%2F%2Fwww.wrox.com%2Fillegal%20value.htm%23start" alert(encodeURIComponent(uri)); decodeURI() 和 decodeURIComponent()
1、decodeURI()只能对使用 encodeURI()替换的字符进行解码。例如, 它可将%20 替换成一个空格,但不会对%23 作任何处理,因为%23 表示井字号(#),而井字号不是使用 encodeURI()替换的。
2、decodeURIComponent()能够解码使用 encodeURIComponent()编码的所有字符,即它可以解码任何特殊字符的编码
例如:
var uri = "http%3A%2F%2Fwww.wrox.com%2Fillegal%20value.htm%23start";
//http%3A%2F%2Fwww.wrox.com%2Fillegal value.htm%23start alert(decodeURI(uri));
//http://www.wrox.com/illegal value.htm#start alert(decodeURIComponent(uri)); eval()
eval()方法就像是一个完整的 ECMAScript 解析器,它只接受一个参数,即要执行的 ECMAScript(或 JavaScript) 字符串(可能是整个 ECMAScript 语言中最强大的一个方法)
例如:
//1
eval("alert('hi')");
//这行代码的作用等价于下面这行代码:
alert("hi");
//当解析器发现代码中调用 eval()方法时,它会将传入的参数当作实际的 ECMAScript 语句来解析, 然后把执行结果插入到原位置。
//2、通过 eval()执行的代码被认为是包含该次调用的执行环境的一部分, 因此被执行的代码具有与该执行环境相同的作用域链
var msg = "hello world";
eval("alert(msg)"); //"hello world"
//可见,变量 msg 是在 eval()调用的环境之外定义的,但其中调用的 alert()仍然能够显示"hello world"。这是因为上面第二行代码最终被替换成了一行真正的代码
eval("function sayHi() { alert('hi'); }");
sayHi();
// sayHi()是在 eval()内部定义的。但由于对 eval()的调用最终会被替换成定义函数的实际代码,因此可以在下一行调用 sayHi()
eval("var msg = 'hello world'; ");
alert(msg); //"hello world" 注意
能够解释代码字符串的能力非常强大,但也非常危险。因此在使用 eval()时必须极为谨慎,特别是在用它执行用户输入数据的情况下。否则,可能会有恶意用户输入威胁你的站点或应用程序安全的代码(即所谓的代码注入)
window对象
ECMAScript 虽然没有指出如何直接访问 Global 对象,但 Web 浏览器都是将这个全局对象作为 window 对象的一部分加以实现的。因此,在全局作用域中声明的所有变量和函数,就都成为了 window 对象的属性
例如:
//1
var color = "red";
function sayColor(){
alert(window.color); }
window.sayColor(); //"red"
//2、另一种取得 Global 对象的方法
var global = function(){
return this; }(); Math对象
min()和 max()方法
min()和 max()方法用于确定一组数值中的最小值和最大值,这两个方法都可以接收任意多个数值参数
var max = Math.max(3, 54, 32, 16); alert(max); //54
var min = Math.min(3, 54, 32, 16); alert(min); //3 舍入方法
| 方法 | 说明 |
|---|---|
| Math.ceil() | 执行向上舍入,即它总是将数值向上舍入为最接近的整数; |
| Math.floor() | 执行向下舍入,即它总是将数值向下舍入为最接近的整数; |
| Math.round() | 执行标准舍入,即它总是将数值四舍五入为最接近的整数 |
例如:
alert(Math.ceil(25.9)); //26 alert(Math.ceil(25.5)); //26 alert(Math.ceil(25.1)); //26
alert(Math.round(25.9)); //26 alert(Math.round(25.5)); //26 alert(Math.round(25.1)); //25
alert(Math.floor(25.9)); //25 alert(Math.floor(25.5)); //25 alert(Math.floor(25.1)); //25 random()方法
Math.random()方法返回大于等于 0 小于 1 的一个随机数,套用下面的公式,就可以利用 Math.random() 从某个整数范围内随机选择一个值
值 = Math.floor(Math.random() * 可能值的总数 + 第一个可能的值)
例如:
//选择一个 1 到 10 之间的数值:
var num = Math.floor(Math.random() * 10 + 1);
//选择一个介于 2 到 10 之间的值
var num = Math.floor(Math.random() * 9 + 2);
//通过一个函数来计算可能值的总数和第一个可能的值
function selectFrom(lowerValue, upperValue) {
var choices = upperValue - lowerValue + 1;
return Math.floor(Math.random() * choices + lowerValue); }
var num = selectFrom(2, 10);
alert(num); // 介于 2 和 10 之间(包括 2 和 10)的一个数值
参考
《JavaScript高级程序设计(第3版)》
作者:iamcgt 发表于2017/9/12 22:50:44 原文链接
阅读:156 评论:0 查看评论
↧
前言
入手游行已经有五年了,一路懵懂 从初级小白到高级小白,旅途中给自己定下了几个目标(坑):
1、自己主导一款游戏的开发
2、自制2D游戏引擎
3、用自制2D引擎 完成一款独立游戏
想实现自己的目标,多少需要一些机会与决断,幸运的是去年有一个机会出现,而自己也决然抓住,至今日已经完成第一个目标,完成了一款游戏的开发。http://www.9game.cn/yonghengxianyu/ 。此后就等待更好的机会吧。
工作差不多一年,被技术总监带进了OpenGL的世界,从此断断续续开始学习,到今天我也只懂贴个图,画个三角形。不过对于我的第二个目标来说,这些又已经够了。所以是时候集中精力来完成我的第二个目标了,来开始我的成就 - 跨平台游戏引擎。
我已经断断续续做了一些工作,项目托管在Github上,https://github.com/ThisisGame/Lives2D ,项目并没有很正式的开发,我也只是把它作为个人的小东西,小而美。我喜欢简单一点,代码尽量简单,结构简单,使用简单。 项目的每开发一个新的阶段,我都会作为一个分支存储,从Version1 到VersionX,就可以了解到我的成就之路。
因为最近沉迷Date A Live 不能自拔,所以项目定名为 Lives2D,无奈,Live2D已经被同行开发了很久了。
我也为Lives2D 开了一个网页 http://www.liveslives.com/ 。从这里可以跳转到Github Repository。
项目最终将转向Lua作为开发语言,目前最新的Branch 已经在为转向Lua 做准备。
敬请关注
作者:cp790621656 发表于2017/9/13 2:10:47 原文链接
阅读:96 评论:0 查看评论
↧
R实战:【常用函数】transform对列数据加工生成新列
↧
↧
《剑指offer》刷题笔记:跳台阶
《剑指offer》刷题笔记:跳台阶
- 转载请注明作者和出处:http://blog.csdn.net/u011475210
- 代码地址:https://github.com/WordZzzz/Note/tree/master/AtOffer
- 刷题平台:https://www.nowcoder.com/
- 题 库:剑指offer
- 编 者:WordZzzz
题目描述:
一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
解题思路:
对于n级台阶,第一步有2种跳法:跳1级、跳2级;
跳1级,剩下n-1级,则剩下跳法是f(n-1)
跳2级,剩下n-2级,则剩下跳法是f(n-2)
所以f(n)=f(n-1)+f(n-2)。
实现f(n)=f(n-1)+f(n-2)的方法有很多种,递归、循环都可以。
C++版代码实现:
递归:
class Solution {
public:
int jumpFloor(int number) {
if(number <= 0)
return 0;
else if(number < 3)
return number;
else
return jumpFloor(number-1)+jumpFloor(number-2);
}
};循环:
class Solution {
public:
int jumpFloor(int number) {
if(number <= 0)
return 0;
else if(number < 3)
return number;
int first = 1, second = 2, third = 0;
for (int i = 3; i <= number; i++) {
third = first + second;
first = second;
second = third;
}
return third;
}
};Python 代码实现:
递归:
# -*- coding:utf-8 -*-
class Solution:
def jumpFloor(self, number):
# write code here
if number <= 0:
return 0
elif number < 3:
return number
else:
return self.jumpFloor(number-1) + self.jumpFloor(number-2)循环:
# -*- coding:utf-8 -*-
class Solution:
def jumpFloor(self, number):
# write code here
if number <= 0:
return 0
elif number < 3:
return number
first = 1
second = 2
third = 0
for i in range(3,number+1):
third = first + second
first = second
second = third
return third;系列教程持续发布中,欢迎订阅、关注、收藏、评论、点赞哦~~( ̄▽ ̄~)~
完的汪(∪。∪)。。。zzz
作者:u011475210 发表于2017/9/13 9:51:41 原文链接
阅读:8 评论:0 查看评论
↧
2017最酷的 30 个 Android 库
这里是 30 个我最喜欢的在 2017 年 3 月前新出现的 Android 库。其中一些并没有用于实际产品,但你使用它们可能会得到很多的乐趣。我希望你们喜欢这些库。
下面的顺序不代表排名:
1.Matisse
这是一个漂亮的本地图片、视频选择器。其主要功能有:
选择包括JPEG、PNG、GIF格式的图片和 MPEG、MP4 格式的视频
支持自定义主题,包括两个内置的主题
不同的图片加载器
定义自定义过滤规则
在 Activities 和 Fragments 中操作良好
你可以在代码库的 wiki 中发现更多。

2. Spruce Android Animation Library (安卓动画库)
Spruce 是一个轻量级的动画库,可以帮助排版屏幕上的动画。使用有很多不同的动画库时,开发人员需要确保每个视图都能够在适当的时间活动。 Spruce 可以帮助设计师获得复杂的多视图动画,而不是让开发人员在原型阶段就感到畏惧。

3. MaterialChipsInput
Chips 是 Material Design 中组件,他们被描述为
小却相对复杂的个体,比如联系人。Chip 可以包含一些独立的东西,比如照片、文本、条款、图标或者联系人。
MaterialChipsInput 是在 Android 中实现的那个组件。这个库提供了两个视图:ChipsInput 和 ChipView.

4. Grav
该库允许基于点创建多个动画。 你可以很容易地制作出光滑美丽的动画。 README 包含很多示例,因此您可以在此处查看.

5. Litho
Litho 不是库,而是一个框架。它是一个非常强大的框架,以声明的方式构建 UI。它由 Facebook 的开发者开发,所以就算你不想使用它,它仍然值得你去关注它的开发过程。

主要特性包括:
使用申明式 API 来定义 UI 组件。你只需要基于一套固定的输入来描述布局就好,其它事情框架会搞定。
异步布局:Litho 可以在不阻碍 UI 线程的情况下计算并对 UI 布局。
扁平化视图:Litho 使用 Yoga 来布局,并自动缩减 UI中 ViewGroups 的数量。
细粒度回收:UI 中任何像 text 或 image 之类的组件都能被回收再利用。
6. Adaptable Bottom Navigation(自适应的底部导航)
不久前 Google 更新了 Material Design 的计划,介绍了底部导航栏,这是个在应用中让 UI 跟随内容变化的不错的方式。设计支持库(Design Support Library) 中也添加了实现。

用自适应底层导航替换支持库中的 BottomNavigationView 非常简单。它以 ViewPager 和 TabLayout 的工作方式来实现。这里有来自开发团队的一个简短说明:
如前所述,使用 Android 支持库中的底部导航视图需要写很多无聊的的代码切换视图。因此,我们根据 TabLayout 的 setupWithViewPater() 方法,创建了独有特色的 ViewSwapper 组件连接到底层导航视图来以一个简单的方式对视图的显示进行管理。
你可以在 Github 中找到更多相关信息。对于为什么要实现这个东西,那里有详尽的资料和说明(提示:结构清晰)。

7. PatternLockView(图形锁视图)
这个库让你可以在应用中简单快速的实现图形锁机制。这个视图真的是非常易用,它有大量的个性化选项可以用于改变功能和外观,以此满足你的需求。
它还支持 RxJava 2 视图绑定,所以如果你喜欢响应式编程(就像我一样),你可以得到用户绘制图形的更新流。
README 中充满了示例,所以入门很容易。

8. Isometric
这是一个有助于绘制等轴形状的库。在我看来,它是本列表中最炫的库之一,因为它让我想起了 Monument Valley 游戏。
该库支持绘制多个形状、路径和复杂结构,如下面的示例:

9. UltraViewPager
UltraViewPager 是一个封装多种特性的 ViewPager ,主要是为多页面切换场景提供统一解决方案。

主要功能
- 支持横向滑动/纵向滑动
- 支持一屏内显示多页
- 支持循环滚动
- 支持定时滚动,计时器使用 Handler 实现
- 支持设置 ViewPager 的最大宽高
- setRatio 按比例显示 UltraviewPager
- 内置 indicator ,只需简单设置几个属性就可以完成展示,支持圆点和 Icon;
- 内置两种页面切换动效
该库有一个非常良好的文档。
10. InfiniteCards
可自定义动效的卡片切换视图,该库有助于实现卡片 UI ,然后用一个漂亮的动画切换它们。

参数
- animType : 动效展示类型
- front : 将点击的卡片切换到第一个
- switchPosition : 将点击的卡片和第一张卡片互换位置
- frontToLast : 将第一张卡片移到最后,后面的卡片往前移动一个
- cardRatio : 卡片宽高比
- animDuration : 卡片动效时间
- animAddRemoveDelay : 卡片组切换时,添加与移出时,相邻卡片展示动效的间隔时间
- animAddRemoveDuration : 卡片组切换时,添加与移出时,卡片动效时间
11. SlidingRootNav
我们可以认为这个库是像 DrawerLayout 的 ViewGroup,drawer(抽屉) 隐藏在内容视图之下,可以通过改变它们来显示 drawer。REAMDE 很全面,值得一看。

12. PasscodeView
这就是一个你可以键入密码的 view。但非常棒!

13. MusicWave
该库允许将声音表示为彩色梯度变化。

14. ShadowImageView
该库可帮助你为图片添加更有意义的阴影。根据 README ,它的作用是:
可以根据图片内容变阴影颜色,更加细腻的阴影效果。
此外,它也非常易于使用。

15. PolygonDrawingUtil
这是一个高效的 Android 实用程序类,用于在 Canvas 上绘制常规的多边形。 我们可以指定:
边数(≥3)
中心点坐标
外接圆半径(从中心到顶点的距离)
圆角半径
多边形旋转度
填充/描边颜色
![]()

16. Tiny
这是本列表中的第二个框架。它负责图像压缩,功能相当强大的。还支持
使用异步线程池来压缩图像,并且当压缩完成时,会将结果发送到主线程中。

17. ParticleTextView
该库提供了一个自定义的 view 组件,可以用彩色粒子组成指定的文字,并配合多种动画效果和配置属性,呈现出丰富的视觉效果。

18. CropIwa
这是一个高可配置的图像裁剪部件。该库基于模块化结构,因此它的可配置性非常强。你可以从 Github 上的 WiKi 了解如何进行配置。

19. Project Condom
『保险套』是一个超轻超薄的 Android 工具库,将它套在 Android 应用工程里裸露的 Context 上,再传入第三方 SDK(通常是其初始化方法),即可防止三方 SDK 中常见的损害用户体验的行为:
在后台启动大量其它应用的进程(在三方推送 SDK 中较为常见),导致应用启动非常缓慢,启动后一段时间内出现严重的卡顿(在中低端机型上尤其明显)。 这是由于在这些 SDK 初始化阶段启动的其它应用中往往也存在三方 SDK 的类似行为,造成了进程启动的『链式反应』,在短时间内消耗大量的 CPU、文件 IO 及内存资源,使得当前应用所能得到的资源被大量挤占(甚至耗尽)。
20. AppMethodOrder
一个能让你了解所有函数调用顺序以及函数耗时的 Android 库(无需侵入式代码)。
当项目代码量很大的时候,或者你作为一名新人要快速掌握代码的时候,给函数打上 log ,来了解代码执行逻辑,这种方式会显然成本太大,要改动项目编译运行,NO!太耗时;或者你想 debug 的方式来给你想关注的几个函数,来了解代码执行逻辑,NO!因为你肯定会漏掉函数;也许你可以固执的给你写的项目打满 log 说这样也行,但是你要知道你方法所调用的 jdk 的函数或者第三方 aar 或者 jar 再或者 android sdk 中的函数调用顺序你怎么办,还能打 log 吗?显然不行吧,来~这个项目给让可以让你以包名为过滤点过滤你想要知道所有函数调用顺序。
项目有详细的文件,你可以找到详细的手册了解如何使用它。

21. Android DebugKit
这是一个有趣的库。它允许你创建和使用特殊的悬停调试工具,以触发你在应用程序中定义的操作。这些操作可以在运行时明显的触发,因此可以在编写或测试手机屏幕反馈时间时使用。
该库使用 Builder 模式。 它很容易使用,在 README 中有一个其用法的示例。

22. Aesthetic
这是一个新的库,仍处于测试版,但它做了一件非常酷的事情 - 它通过 Rx 支持动态改变系统主题! 作者是这么描述的:
一个快速和易于使用的即插即用的动态主题引擎。由 Rx 支持,适用于 Android 应用。
该库文档非常不错、内容全面,值得一读。

23. EasyCalendar
这是一个简单的自定义日历小插件。 主要功能包括:
自定义布局的标题
自定义布局的日期
显示或隐藏日期的分隔符
显示或隐藏溢出的日期
监听日期视图的点击操作
该库的文档是全面且易于使用的。

24. SimpleRatingBar
该库提供两个评分栏:
BaseRatingBar - 没有任何动画
ScaleRatingBar - 具有渐进和缩放动画
你可以在下面的 gif 图中看到它们的效果:

25. Magellan
这个库被标榜为最简单的 Android 导航库,但你仍然需要自己判断它是否适合自己使用。主要特性:
调用 goTo(screen) 方法就能简单实现导航,
返回栈完全可控,
自动处理过渡。
wiki 上有全面的说明。

26. ViewPagerAnimator
ViewPagerAnimator 是一款面向 Android 的轻量级、功能强大的 ViewPager 动画库。 它被设计为在用户在 ViewPager 中的页面之间导航时显示任意动画,并且将精确地跟随他或她的手指的动作。虽然该库本身可能对某些人有用,但是发布这个库的主要目的就是展示一些完美 API 的细节之处,在使用即将到来的 Java 8 扩展时,这真的是走在前列的。本库还提供了 Java 7 和 Java 8 的示例项目。
它是由 Mark Allison 写的,你可以在他的 Styling Android 博客上获得更多的信息。

27. BlockCanaryEx
这是一个当你的应用程序被阻塞时,它可以方便在代码中找到阻塞的方法的库。它是基于 BlockCanary 的。

28. PaletteImageView
非常酷的一个库,可以动态的提取图片的主要颜色,并将颜色作为图片阴影的控件。

该项目文档较少,但我认为代码是不言自明的。
29. RecyclerRefreshLayout
这是一个打开相机快门的刷新动画。在我看来,真的值得研究,特别是在 README 中有一个关于如何实现这个效果的数学分析!

30. SlimAdapter
这是一种不使用 ViewHolder 来编写适配器的方法。主要功能包括:
不包含 ViewHolders
没有反射
流畅和简单的 API
支持多类型适配器
支持 Kotlin
支持简单的 DiffUtil
![]()

以上。希望你喜欢这篇文章! 如果还有在今年发布的其他伟大的库我没有提到,请在下面回复让我知道。 让我们一起维护这个列表!
作者:gsg8709 发表于2017/9/13 10:12:46 原文链接
阅读:0 评论:0 查看评论
↧
android 个人中心下拉弹回效果-PullscrollView
实现效果:
这个效果就是仿qq个人中心的下拉弹回效果实现。
核心就是一个 自定义的ScrollView,如下:
package com.baobao.testpullscrollview;
import android.annotation.SuppressLint;
import android.content.Context;
import android.content.res.TypedArray;
import android.graphics.Rect;
import android.util.AttributeSet;
import android.view.MotionEvent;
import android.view.View;
import android.view.animation.TranslateAnimation;
import android.widget.ScrollView;
public class PullScrollView extends ScrollView {
/** 阻尼系数,越小阻力就越大. */
private static final float SCROLL_RATIO = 0.5f;
/** 滑动至翻转的距离. */
private static final int TURN_DISTANCE = 100;
/** 头部view. */
private View mHeader;
/** 头部view高度. */
private int mHeaderHeight;
/** 头部view显示高度. */
private int mHeaderVisibleHeight;
/** ScrollView的content view. */
private View mContentView;
/** ScrollView的content view矩形. */
private Rect mContentRect = new Rect();
/** 首次点击的Y坐标. */
private float mTouchDownY;
/** 是否关闭ScrollView的滑动. */
private boolean mEnableTouch = false;
/** 是否开始移动. */
private boolean isMoving = false;
/** 是否移动到顶部位置. */
private boolean isTop = false;
/** 头部图片初始顶部和底部. */
private int mInitTop, mInitBottom;
/** 头部图片拖动时顶部和底部. */
private int mCurrentTop, mCurrentBottom;
/** 状态变化时的监听器. */
private OnTurnListener mOnTurnListener;
private enum State {
/**顶部*/
UP,
/**底部*/
DOWN,
/**正常*/
NORMAL
}
/** 状态. */
private State mState = State.NORMAL;
public PullScrollView(Context context) {
super(context);
init(context, null);
}
public PullScrollView(Context context, AttributeSet attrs) {
super(context, attrs);
init(context, attrs);
}
public PullScrollView(Context context, AttributeSet attrs, int defStyle) {
super(context, attrs, defStyle);
init(context, attrs);
}
@SuppressLint("NewApi")
private void init(Context context, AttributeSet attrs) {
// set scroll mode
setOverScrollMode(OVER_SCROLL_NEVER);
if (null != attrs) {
TypedArray ta = context.obtainStyledAttributes(attrs, R.styleable.PullScrollView);
if (ta != null) {
mHeaderHeight = (int) ta.getDimension(R.styleable.PullScrollView_headerHeight, -1);
mHeaderVisibleHeight = (int) ta.getDimension(R.styleable
.PullScrollView_headerVisibleHeight, -1);
ta.recycle();
}
}
}
/**
* 设置Header
*
* @param view
*/
public void setHeader(View view) {
mHeader = view;
}
/**
* 设置状态改变时的监听器
*
* @param turnListener
*/
public void setOnTurnListener(OnTurnListener turnListener) {
mOnTurnListener = turnListener;
}
@Override
protected void onFinishInflate() {
if (getChildCount() > 0) {
mContentView = getChildAt(0);
}
}
@Override
protected void onScrollChanged(int l, int t, int oldl, int oldt) {
super.onScrollChanged(l, t, oldl, oldt);
if (getScrollY() == 0) {
isTop = true;
}
}
@Override
public boolean onInterceptTouchEvent(MotionEvent ev) {
if (ev.getAction() == MotionEvent.ACTION_DOWN) {
mTouchDownY = ev.getY();
mCurrentTop = mInitTop = mHeader.getTop();
mCurrentBottom = mInitBottom = mHeader.getBottom();
}
return super.onInterceptTouchEvent(ev);
}
@Override
public boolean onTouchEvent(MotionEvent ev) {
if (mContentView != null) {
doTouchEvent(ev);
}
// 禁止控件本身的滑动.
return mEnableTouch || super.onTouchEvent(ev);
}
/**
* 触摸事件处理
*
* @param event
*/
private void doTouchEvent(MotionEvent event) {
int action = event.getAction();
switch (action) {
case MotionEvent.ACTION_MOVE:
doActionMove(event);
break;
case MotionEvent.ACTION_UP:
// 回滚动画
if (isNeedAnimation()) {
rollBackAnimation();
}
if (getScrollY() == 0) {
mState = State.NORMAL;
}
isMoving = false;
mEnableTouch = false;
break;
default:
break;
}
}
/**
* 执行移动动画
*
* @param event
*/
private void doActionMove(MotionEvent event) {
// 当滚动到顶部时,将状态设置为正常,避免先向上拖动再向下拖动到顶端后首次触摸不响应的问题
if (getScrollY() == 0) {
mState = State.NORMAL;
// 滑动经过顶部初始位置时,修正Touch down的坐标为当前Touch点的坐标
if (isTop) {
isTop = false;
mTouchDownY = event.getY();
}
}
float deltaY = event.getY() - mTouchDownY;
// 对于首次Touch操作要判断方位:UP OR DOWN
if (deltaY < 0 && mState == State.NORMAL) {
mState = State.UP;
} else if (deltaY > 0 && mState == State.NORMAL) {
mState = State.DOWN;
}
if (mState == State.UP) {
deltaY = deltaY < 0 ? deltaY : 0;
isMoving = false;
mEnableTouch = false;
} else if (mState == State.DOWN) {
if (getScrollY() <= deltaY) {
mEnableTouch = true;
isMoving = true;
}
deltaY = deltaY < 0 ? 0 : deltaY;
}
if (isMoving) {
// 初始化content view矩形
if (mContentRect.isEmpty()) {
// 保存正常的布局位置
mContentRect.set(mContentView.getLeft(), mContentView.getTop(), mContentView.getRight(),
mContentView.getBottom());
}
// 计算header移动距离(手势移动的距离*阻尼系数*0.5)
float headerMoveHeight = deltaY * 0.5f * SCROLL_RATIO;
mCurrentTop = (int) (mInitTop + headerMoveHeight);
mCurrentBottom = (int) (mInitBottom + headerMoveHeight);
// 计算content移动距离(手势移动的距离*阻尼系数)
float contentMoveHeight = deltaY * SCROLL_RATIO;
// 修正content移动的距离,避免超过header的底边缘
int headerBottom = mCurrentBottom - mHeaderVisibleHeight;
int top = (int) (mContentRect.top + contentMoveHeight);
int bottom = (int) (mContentRect.bottom + contentMoveHeight);
if (top <= headerBottom) {
// 移动content view
mContentView.layout(mContentRect.left, top, mContentRect.right, bottom);
// 移动header view
mHeader.layout(mHeader.getLeft(), mCurrentTop, mHeader.getRight(), mCurrentBottom);
}
}
}
private void rollBackAnimation() {
TranslateAnimation tranAnim = new TranslateAnimation(0, 0,
Math.abs(mInitTop - mCurrentTop), 0);
tranAnim.setDuration(200);
mHeader.startAnimation(tranAnim);
mHeader.layout(mHeader.getLeft(), mInitTop, mHeader.getRight(), mInitBottom);
// 开启移动动画
TranslateAnimation innerAnim = new TranslateAnimation(0, 0, mContentView.getTop(), mContentRect.top);
innerAnim.setDuration(200);
mContentView.startAnimation(innerAnim);
mContentView.layout(mContentRect.left, mContentRect.top, mContentRect.right, mContentRect.bottom);
mContentRect.setEmpty();
// 回调监听器
if (mCurrentTop > mInitTop + TURN_DISTANCE && mOnTurnListener != null){
mOnTurnListener.onTurn();
}
}
/**
* 是否需要开启动画
*/
private boolean isNeedAnimation() {
return !mContentRect.isEmpty() && isMoving;
}
/**
* 翻转事件监听器
*
* @author markmjw
*/
public interface OnTurnListener {
/**
* 翻转回调方法
*/
public void onTurn();
}
}
调用Activity
package com.baobao.testpullscrollview;
import android.app.Activity;
import android.os.Bundle;
import android.widget.ImageView;
public class MainActivity extends Activity implements PullScrollView.OnTurnListener{
private PullScrollView mScrollView;
private ImageView mHeadImg;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
mScrollView = (PullScrollView) findViewById(R.id.scroll_view);
mHeadImg = (ImageView) findViewById(R.id.background_img);
mScrollView.setHeader(mHeadImg);
mScrollView.setOnTurnListener(this);
}
@Override
public void onTurn() {
// TODO Auto-generated method stub
}
}
xml文件:
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:background="@color/white"
android:orientation="vertical" >
<ImageView
android:id="@+id/background_img"
android:layout_width="match_parent"
android:layout_height="300dp"
android:layout_marginTop="-100dp"
android:contentDescription="@null"
android:scaleType="fitXY"
android:src="@drawable/scrollview_header" />
<com.baobao.testpullscrollview.PullScrollView
android:id="@+id/scroll_view"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:fillViewport="true"
app:headerHeight="300dp"
app:headerVisibleHeight="100dp" >
<LinearLayout
android:layout_width="match_parent"
android:layout_height="match_parent"
android:background="@color/transparent"
android:orientation="vertical" >
<RelativeLayout
android:id="@+id/scroll_view_head"
android:layout_width="match_parent"
android:layout_height="112dp"
android:layout_marginTop="100dp"
android:background="@color/transparent"
android:orientation="vertical" >
<ImageView
android:id="@+id/user_avatar"
android:layout_width="68dp"
android:layout_height="68dp"
android:layout_marginLeft="21dp"
android:background="@android:color/white"
android:contentDescription="@null"
android:padding="1px"
android:src="@drawable/avatar_default" />
<TextView
android:id="@+id/user_name"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_marginLeft="13dp"
android:layout_toRightOf="@id/user_avatar"
android:ellipsize="end"
android:shadowColor="@android:color/black"
android:shadowDx="3.0"
android:shadowDy="3.0"
android:shadowRadius="5.0"
android:singleLine="true"
android:text="@string/user_name"
android:textColor="@android:color/white"
android:textSize="20sp" />
<FrameLayout
android:id="@+id/user_divider_layout"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:layout_below="@id/user_avatar"
android:layout_marginLeft="21dp"
android:layout_marginRight="21dp"
android:layout_marginTop="4dp" >
<ImageView
android:layout_width="match_parent"
android:layout_height="1px"
android:layout_marginTop="5dp"
android:background="#DFDFDF"
android:contentDescription="@null" />
<ImageView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_marginLeft="29dp"
android:contentDescription="@null"
android:src="@drawable/arrow_up" />
</FrameLayout>
</RelativeLayout>
</LinearLayout>
</com.baobao.testpullscrollview.PullScrollView>
</RelativeLayout>实现效果图如上图,最后给大家奉上 DEMO源码下载
如果大家demo下载有问题或者有其他问题
欢迎加入我的qq群:开发一群:454430053开发二群:537532956
作者:shaoyezhangliwei 发表于2017/9/13 10:20:25 原文链接
阅读:3 评论:0 查看评论
↧