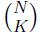本文demo源码、实验数据:传送门
引言
如题,关联分析这个词语对于初学者而言或许比较陌生。但是我若将关联分析换成另一个短语“尿布与啤酒”大家就会很熟悉了。据报道,美国中西部的一家连锁店发现,男人们会在周四购买尿布和啤酒。这样商店实际上可以将尿布和啤酒放在一块,并确保在周四的销售中获利。“尿布与啤酒”是关联分析中最著名的例子。那么关联分析的定义也就呼之欲出了:从大规模数据集中寻找物品间的隐含关系被称作关联分析或者关联规则学习。但是寻找物品之间的隐含关系是一项十分耗时的任务,所需的计算代价很高,这就催生出了Apriori算法来在合理的时间范围内解决上述问题。
频繁项集、关联分析
关联分析是一种在大规模数据集中寻找有趣关系的任务。这些关系可以有两种形式:频繁项集或关联规则。频繁项集是经常出现在一起的物品的集合,关联规则按时两种物品之间可能存在很强的关系。我们来举个例子来说明这两个概念。下图给出了某个杂货店的交易清单。
![grocery store]()
频繁项是指那些经常出现在一起的物品集合,如上图所示的{diapers,wine}就是频繁项集的一个例子。从上图中我们也能找到诸如diapers→wine的关联规则。这意味着如果有人买了diapers,那么他很可能也会买wine。
量化的方法–支持度、置信度
如何判断数据集中存在这种关系,如何量化数据从而得到判断这些关系是否存在的标准呢?有人提出了支持度(support)和置信度(confidence)的概念。
一个项集的支持度被定义为数据集中包含该项的记录所占的比例。如上图所示,{soy milk}的支持度为4/5。支持度是针对项集来说的,因此可以定义一个最小支持度,而只保留满足最小支持度的项集。置信度是针对诸如diapers→wine的关联规则来定义的。这条规则的置信度被定义为:支持度({diapers,wine})/支持度({diapers})。这一定义也可以用条件概率来解释:
P(diapers,wine)=P(wine|diapers)P(diapers)
大家看到这个条件概率是不是很惊奇?其实从apriori这里我们就能发现一丝端倪了。Apriori在拉丁语中指”来自以前”。当定义问题时,通常会使用先验知识或者假设,这被称作“一个先验”(apriori)。在贝叶斯统计中,使用先验知识作为条件进行推断也很正常。
支持度和置信度是用来量化关联分析是否成功的方法。假设想找到支持度大于0.8的所有项集,应该如何去做?或许有人会想到“贪心”的方法,就是生成一个物品所有可能组合的清单,然后对每一种组合统计它出现的频繁程度,但是当物品成千上万时,上述做法就需要消耗大量的计算资源。因此有人提出了Apriori算法来减少关联规则学习时所需的计算量。
Apriori原理
我们以经营一家商品种类并不多的杂货店为例。我们总共有四种商品:商品0,商品1,商品2,商品3。那么这四种商品所有可能的项集组合如下所示:
![possible]()
对于仅有4种物品的集合,也要有15种项集组合。对于N种物品的集合,就有2N−1种项集组合。
这种项集组合个数指数型增长将会消耗极大的计算资源。那么,到底有没有一种方法能够降低所需要的计算时间呢?
Apriori原理
研究人员发现了一种所谓的Apriori原理。这种原理可以帮助我们减少可能感兴趣的项集。为什么Apriori原理能够减少计算时间呢?那是因为在数据中,如果某个项集是频繁的,那么它的所有子集都是频繁地。反之,如果一个项集是非频繁的,那么它的所有超集也》
![association]()
上图给出了所有可能的项集,其中非频繁项用灰色表示。由于集合{2,3}是非频繁的,因此{0,2,3}、{1,2,3}、{0,1,2,3}也是非频繁的,它们的支持度根本不需要计算。
使用Apriori算法来发现频繁项集
前面我们有说,关联分析的目标包括两项:发现频繁项集和发现关联规则。首先需要先找到频繁项集,然后才能获得关联规则。
Apriori算法是发现频繁项集的一种方法。Apriori算法的两个输入参数分别是最小支持度和数据集。该算法首先会生成所有单个物品的项集列表。接着扫描交易记录来查看哪些项集满足最小支持度的要求,那些不满足最小支持度的集合会被去掉。然后,对剩下来的集合进行组合以生成包含两个元素的项集。接下来,再重新扫描交易记录,去掉不满足最小支持度的项集。该过程重复进行直到满足退出条件。
生成候选项集
下面会创建一个用于构建初始集合的函数,也会创建一个通过扫描数据集以寻找交易记录子集的函数。数据集扫描的伪代码如下:
![这里写图片描述]()
实际代码如下:
def loadDataSet():
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return list(map(frozenset, C1))
def scanD(D, Ck, minSupport):
ssCnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid):
if not can in ssCnt: ssCnt[can]=1
else: ssCnt[can] += 1
numItems = float(len(D))
retList = []
supportData = {}
for key in ssCnt:
support = ssCnt[key]/numItems
if support >= minSupport:
retList.insert(0,key)
supportData[key] = support
return retList, supportData
我们一共有三个函数,第一个函数loadDataSet()
用来构建交易记录,一共四条交易记录,商品种类一共5种。第二个函数是createC1()这里C1是指大小为1的所有候选项集的集合。第三个函数scanD(),它有三个参数,分别是数据集、候选集列表Ck以及感兴趣项集的最小支持度minSupport。
我们来看实际的运行效果:
import importlib
import apriori
dataSet = apriori.loadDataSet()
dataSet
[[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
importlib.reload(apriori)
C1 = apriori.createC1(dataSet)
C1
[frozenset({1}),
frozenset({2}),
frozenset({3}),
frozenset({4}),
frozenset({5})]
L1 ,suppData0 = apriori.scanD(dataSet,C1,0.5)
L1
[frozenset({5}), frozenset({2}), frozenset({3}), frozenset({1})]
上述四个项集构成了L1列表,该列表的每个但物品项集至少出现在50%以上的记录中。这通过去掉物品4,从而为接下来寻找两两物品组合的项集减少了工作量。
完整的Apriori算法
整个Apriori算法的伪代码如下:
![algorithm]()
完整的代码如下:
def aprioriGen(Lk, k):
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1, lenLk):
L1 = list(Lk[i])[:k-2]; L2 = list(Lk[j])[:k-2]
L1.sort(); L2.sort()
if L1==L2:
retList.append(Lk[i] | Lk[j])
return retList
def apriori(dataSet, minSupport = 0.5):
C1 = createC1(dataSet)
D = dataSet
L1, supportData = scanD(D, C1, minSupport)
L = [L1]
k = 2
while (len(L[k-2]) > 0):
Ck = aprioriGen(L[k-2], k)
Lk, supK = scanD(D, Ck, minSupport)
supportData.update(supK)
L.append(Lk)
k += 1
return L, supportData
上述代码由两个函数组成,主函数是apriori(),它会调用aprioriGen()来创建候选集Ck。其中有句代码需要注意下:
L1 = list(Lk[i])[:k-2]; L2 = list(Lk[j])[:k-2]
这里的k-2或许大家不是很清楚,k是指要生成的元素个数,假设有项集{0,1},{0,2},{1,2}那么如果两两集合合并,就会得到重复项,为了减少遍历列表时的时间复杂度,我们发现如果比较集合的前k-2个元素是否相等,相等便合并,不想等不合并。按这个规则合并,不仅结果一样,而且没有重复计算的过程。
具体实验结果如下:
importlib.reload(apriori)
L,suppData = apriori.apriori(dataSet)
L
[[frozenset({5}), frozenset({2}), frozenset({3}), frozenset({1})],
[frozenset({2, 3}), frozenset({3, 5}), frozenset({2, 5}), frozenset({1, 3})],
[frozenset({2, 3, 5})],
[]]
L[0]
[frozenset({5}), frozenset({2}), frozenset({3}), frozenset({1})]
L[1]
[frozenset({2, 3}), frozenset({3, 5}), frozenset({2, 5}), frozenset({1, 3})]
L[2]
[frozenset({2, 3, 5})]
L[3]
[]
从频繁项集中挖掘关联规则
前面我们介绍了Apriori原理,然后实现了Apriori算法来发现频繁项集,现在我们就来找出关联规则。要想找到关联规则,首先就要从频繁项集入手。我们希望从某个元素或者某个元素集合去推导出另一个元素或集合。
从杂货店的例子,我们可以得到如果存在一个频繁项集{diapers,wine},那么就可能有一条关联规则“diaper→wine”,这意味着如果有人购买了diapers,那么他购买wine的概率会很大。但是反之并不一定成立。我们前面给出了关联规则置信度的量化定义。在这里一条规则
“diaper→wine”的置信度定义为support(diaper,wine)/support(diapers)。所以现在看来,要想求关联规则,就先获取置信度,而置信度通过公式就是将前面求得的支持度做了个除法。
那么从一个频繁项集中,能够生成多少规则呢?我们假设频繁项集{0,1,2,3}那么下图给出了关联规则网格示意图。
![grid]()
与频繁项集的生成类似,我们也能找到一个原理来减少规则数目从而降低计算量。图中阴影部分给出了低置信度的规则,可以观察得到,如果某条规则并不满足最小置信度要求,那么该规则的所有子集也不会满足最小置信度要求。与前面讲述的apriori算法类似,首先从一个频繁项集开始,接着创建一个规则列表,其中规则右部只包含元素,然后对这些规则进行测试。接下来合并所有剩余规则来创建一个新的规则列表,其中规则右部包含两个元素。这种方法也被称作分级法。
下面我们直接给出该算法的实现代码:
def generateRules(L, supportData, minConf=0.7):
bigRuleList = []
for i in range(1, len(L)):
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if (i > 1):
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
else:
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
prunedH = []
for conseq in H:
conf = supportData[freqSet]/supportData[freqSet-conseq]
if conf >= minConf:
print(freqSet-conseq,'-->',conseq,'conf:',conf)
brl.append((freqSet-conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
if (len(freqSet) > (m + 1)):
Hmp1 = aprioriGen(H, m+1)
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1):
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
上述代码一共有三个函数,其中第一个函数generateRules()是主函数,其余两个函数rulesFromConseq()和calcConf分别用于生成候选规则集合以及对规则进行评估。
看一下实际运行效果:
L,suppData = apriori.apriori(dataSet,minSupport=0.5)
rules =apriori.generateRules(L,suppData,minConf=0.7)
rules
frozenset({5}) --> frozenset({2}) conf: 1.0
frozenset({2}) --> frozenset({5}) conf: 1.0
frozenset({1}) --> frozenset({3}) conf: 1.0
[(frozenset({5}), frozenset({2}), 1.0),
(frozenset({2}), frozenset({5}), 1.0),
(frozenset({1}), frozenset({3}), 1.0)]
总结
关联分析是用于发现大数据集中元素间有趣关系的一个工具集,可以采用两种方式来量化这些有趣的关系。第一种是频繁项集,第二种是关联规则。发现元素项间不同的组合是个十分耗时的任务,这就需要一些更智能的方法,比如Apriori算法来降低时间复杂度。但是这种算法还是存在问题的,因为在每次增加频繁项集的大小,Apriori都会重新扫描整个数据集。当数据集很大时,这回显著降低频繁项集发现的速度。FP-growth算法就能很好的解决这个问题。
作者:u010665216 发表于2017/11/8 14:03:41
原文链接