Android View控件的事件派发
引:一直想写View,GroupView控件的事件派发流程.终于现在一口气都写出来.一鼓作气!当然考虑了很久应该用怎么样的方式写这些流程性的东西,应该用什么用的语言来描述.后来想就按照聊天的方式把!尽量把整个派发过程都写下来,并且实现一个简单的山寨派发流程.有点只见树不见山的感觉.但是觉得自己写一次view的事件派发胜过再多的理论!
派发流程
首先我们来看看view的事件派发.
关键函数
public boolean dispatchTouchEvent(MotionEvent event);
public boolean onTouchEvent(MotionEvent event);
看看一个简单的”演示代码-1”.
继承view并且在dispatchTouchEvent和onTouchEvent添加打印信息.
MainActivity.java
package com.dsliang.eventdispatch;
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
}
}
EventDispatchView.java
package com.dsliang.eventdispatch;
import android.content.Context;
import android.util.AttributeSet;
import android.util.Log;
import android.view.MotionEvent;
import android.view.View;
/**
* Created by dsliang on 16-7-31.
*/
public class EventDispatchView extends View {
public static String Tag = EventDispatchView.class.getSimpleName();
public EventDispatchView(Context context) {
super(context);
}
public EventDispatchView(Context context, AttributeSet attrs) {
super(context, attrs);
}
public EventDispatchView(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
}
@Override
public boolean dispatchTouchEvent(MotionEvent event) {
boolean result;
Log.d(Tag, "dispatchTouchEvent: " + event.getAction());
result = super.dispatchTouchEvent(event);
Log.d(Tag, "dispatchTouchEvent result: " + result);
return result;
}
@Override
public boolean onTouchEvent(MotionEvent event) {
boolean result;
Log.d(Tag, "onTouchEvent: " + event.getAction());
result = super.onTouchEvent(event);
Log.d(Tag, "onTouchEvent result: " + result);
return result;
}
}
activity_main.xml
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical">
<com.dsliang.eventdispatch.EventDispatchView
android:layout_width="match_parent"
android:layout_height="60dp"
android:background="@android:color/darker_gray" />
</LinearLayout>
![这里写图片描述]()
其实在上面的”演示代码-1”里面我们其实什么事情都没处理.看看在模拟器上运行的效果是怎么样把.
结论:当我们点击红色区域的时候.先后打印出dispatchTouchEvent,onTouchEvent.在这里我们可以知道分发过程必定是先调用dispatchTouchEvent函数然后再调用onTouchEvent函数.
如果你的代码这样写,那么对于我这篇文章你就没必要继续看下去了.事实上我的代码不应该这样写!
一切起于零
然后看看接下来的”演示代码-2”.我们仅仅修改文件EventDispatchView.java文件.
EventDispatchView.java
package com.dsliang.eventdispatch;
import android.content.Context;
import android.util.AttributeSet;
import android.util.Log;
import android.view.MotionEvent;
import android.view.View;
/**
* Created by dsliang on 16-7-31.
*/
public class EventDispatchView extends View {
public static String Tag = EventDispatchView.class.getSimpleName();
public EventDispatchView(Context context) {
super(context);
}
public EventDispatchView(Context context, AttributeSet attrs) {
super(context, attrs);
}
public EventDispatchView(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
}
@Override
public boolean dispatchTouchEvent(MotionEvent event) {
boolean result;
Log.d(Tag, "dispatchTouchEvent: " + event.getAction());
result = false;
Log.d(Tag, "dispatchTouchEvent result: " + result);
return result;
}
@Override
public boolean onTouchEvent(MotionEvent event) {
boolean result;
Log.d(Tag, "onTouchEvent: " + event.getAction());
result = false;
Log.d(Tag, "onTouchEvent result: " + result);
return result;
}
}
我们在dispatchTouchEvent函数里面返回false并且调用父类的dispatchTouchEvent方法.对onTouchEvent函数我们也进行同样的修改.(对于此时,两个函数的返回值是true/false对目前)
![这里写图片描述]()
结论:很明显能看到onTouchEvent函数并没有调用.那么就是说明其实在父类的dispatchTouchEvent里面一定是调用了onTouchEvent函数.
小试牛刀
这个道理你懂了以后我们要达到父类的相同效果,我们现在就针对dispatchTouchEvent进行一番修改.
现在我们也是只修改EventDispatchView.java文件.
EventDispatchView.java
package com.dsliang.eventdispatch;
import android.content.Context;
import android.util.AttributeSet;
import android.util.Log;
import android.view.MotionEvent;
import android.view.View;
/**
* Created by dsliang on 16-7-31.
*/
public class EventDispatchView extends View {
public static String Tag = EventDispatchView.class.getSimpleName();
public EventDispatchView(Context context) {
super(context);
}
public EventDispatchView(Context context, AttributeSet attrs) {
super(context, attrs);
}
public EventDispatchView(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
}
@Override
public boolean dispatchTouchEvent(MotionEvent event) {
boolean result;
Log.d(Tag, "dispatchTouchEvent: " + event.getAction());
result = doOnDispatchTouchEvent(event);
Log.d(Tag, "dispatchTouchEvent result: " + result);
return result;
}
private boolean doOnDispatchTouchEvent(MotionEvent event) {
return onTouchEvent(event);
}
@Override
public boolean onTouchEvent(MotionEvent event) {
boolean result;
Log.d(Tag, "onTouchEvent: " + event.getAction());
result = false;
Log.d(Tag, "onTouchEvent result: " + result);
return result;
}
}
添加doOnDispatchTouchEvent函数,在dispatchTouchEvent调用doOnDispatchTouchEvent函数,doOnDispatchTouchEvent函数调用onTouchEvent函数.这样修改效果基本就和父类有一样的行为了.
![这里写图片描述]()
从上面的效果图也可以看出的确现在这样修改以后和"演示代码-1"行为上看起来好像已经是一致了.
但是现在我又注意到一个问题!event.getAction函数返回是0?进去MotionEvent类看看0代表什么.其实0就是ACTION_DOWN.原来是按钮按下事件.但是也是不科学吧?稍稍有android事件的常事我们都会意识到.点击过程至少会有三个事件会触发.分别是按下,移动,抬起.怎么说再不赖也得有抬起事件把?
![这里写图片描述]()
来到这里,首先抛出一个结论.如果dispatchTouchEvent在按下事件返回false说明此控件并没有消耗此次事件.那么系统(在view的角度触发你可以认为是系统,但是准确来说应该是你的包含你空间的布局容器)会认为你对接下来的一系列事件(移动,抬起)都不感兴趣.简单说就是在收到按下事件的时候返回false,接下来的移动,抬起事件都不会传递到次控件.(这个结论在下一篇”Android GroupView控件的事件派发”会具体阐述说明)
稍稍做润色
嗯嗯,那么稍稍把onTouchEvent的会返回值修改一下.这个就是我们的”演示代码-3”了.同样也是只修改EventDispatchView.java文件.
EventDispatchView.java
package com.dsliang.eventdispatch;
import android.content.Context;
import android.util.AttributeSet;
import android.util.Log;
import android.view.MotionEvent;
import android.view.View;
/**
* Created by dsliang on 16-7-31.
*/
public class EventDispatchView extends View {
public static String Tag = EventDispatchView.class.getSimpleName();
public EventDispatchView(Context context) {
super(context);
}
public EventDispatchView(Context context, AttributeSet attrs) {
super(context, attrs);
}
public EventDispatchView(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
}
@Override
public boolean dispatchTouchEvent(MotionEvent event) {
boolean result;
Log.d(Tag, "dispatchTouchEvent: " + event.getAction());
result = doOnDispatchTouchEvent(event);
Log.d(Tag, "dispatchTouchEvent result: " + result);
return result;
}
private boolean doOnDispatchTouchEvent(MotionEvent event) {
return onTouchEvent(event);
}
@Override
public boolean onTouchEvent(MotionEvent event) {
boolean result;
Log.d(Tag, "onTouchEvent: " + event.getAction());
result = true;
Log.d(Tag, "onTouchEvent result: " + result);
return result;
}
}
现在这样可以看的按下,移动,抬起都派发给我们的EventDispatchView控件了!
![这里写图片描述]()
现在我们先来一个小总结.
1,dispatchTouchEvent函数会调用onTouchEvent函数
2,只有在按下到来的时候dispatchTouchEvent返回true才会接收到移动,抬起事件.
初试锋芒
看起来这一节应该是结束的节奏了吧?图样图森破了!
你是忘了在使用控件的时候,可以设置点击事件和接听滑动事件么?
接下来看看”演示代码-4”.为了突出点击事件,滑动事件.dispatchTouchEvent和onTouchEvent只调用父类的方法.另外给EventDispatchView设置点击事件和滑动事件的监听函数.
MainActivity.java
package com.dsliang.eventdispatch;
import android.app.Activity;
import android.os.Bundle;
import android.util.Log;
import android.view.MotionEvent;
import android.view.View;
public class MainActivity extends Activity {
public static String Tag = MainActivity.class.getSimpleName();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
View view = findViewById(R.id.viewEventDispatchView);
view.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
Log.d(Tag, "onClick");
}
});
view.setOnTouchListener(new View.OnTouchListener() {
@Override
public boolean onTouch(View view, MotionEvent motionEvent) {
Log.d(Tag, "onTouch");
return true;
}
});
}
}
EventDispatchView.java
package com.dsliang.eventdispatch;
import android.content.Context;
import android.util.AttributeSet;
import android.util.Log;
import android.view.MotionEvent;
import android.view.View;
/**
* Created by dsliang on 16-7-31.
*/
public class EventDispatchView extends View {
public static String Tag = EventDispatchView.class.getSimpleName();
public EventDispatchView(Context context) {
super(context);
}
public EventDispatchView(Context context, AttributeSet attrs) {
super(context, attrs);
}
public EventDispatchView(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
}
@Override
public boolean dispatchTouchEvent(MotionEvent event) {
boolean result;
Log.d(Tag, "dispatchTouchEvent: " + event.getAction());
result = super.dispatchTouchEvent(event);
Log.d(Tag, "dispatchTouchEvent result: " + result);
return result;
}
private boolean doOnDispatchTouchEvent(MotionEvent event) {
return onTouchEvent(event);
}
@Override
public boolean onTouchEvent(MotionEvent event) {
boolean result;
Log.d(Tag, "onTouchEvent: " + event.getAction());
result = super.onTouchEvent(event);
Log.d(Tag, "onTouchEvent result: " + result);
return result;
}
}
activity_main.xml
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical">
<com.dsliang.eventdispatch.EventDispatchView
android:id="@+id/viewEventDispatchView"
android:layout_width="match_parent"
android:layout_height="60dp"
android:background="@android:color/darker_gray" />
</LinearLayout>
这里有两个地方需要注意:
1,onTouch函数返回false.onTouch函数的返回值会对派发事件有什么影响?
2,dispatchTouchEvent函数和onTouchEvent函数均使用父类方法的返回值作为返回值.意味着我们只能获取到按下事件.(并没有消耗按下事件)
![这里写图片描述]()
仔细看看,当我们设置了点击事件监听函数之后super.onTouchEvent(event)居然返回true了!不科学呀,明显很之前的有矛盾把?
先给出结论:设置了点击事件回调函数后会改变super.onTouchEvent函数的默认行为.
/**
* Register a callback to be invoked when this view is clicked. If this view is not
* clickable, it becomes clickable.
*
* @param l The callback that will run
*
* @see #setClickable(boolean)
*/
public void setOnClickListener(@Nullable OnClickListener l) {
if (!isClickable()) {
setClickable(true);
}
getListenerInfo().mOnClickListener = l;
}
...
/**
* Enables or disables click events for this view. When a view
* is clickable it will change its state to "pressed" on every click.
* Subclasses should set the view clickable to visually react to
* user's clicks.
*
* @param clickable true to make the view clickable, false otherwise
*
* @see #isClickable()
* @attr ref android.R.styleable#View_clickable
*/
public void setClickable(boolean clickable) {
setFlags(clickable ? CLICKABLE : 0, CLICKABLE);
}
...
设置点击回调函数以后,setClickable函数将CLICKABLE置1了.(flags的CLICKABLE位).
public boolean onTouchEvent(MotionEvent event) {
...
/*
当设置了点击事件回调函数,次条件成立.然后无论是
ACTION_UP,ACTION_DOWN,ACTION_CANCEL,ACTION_MOVE都返回true
*/
if (((viewFlags & CLICKABLE) == CLICKABLE ||
(viewFlags & LONG_CLICKABLE) == LONG_CLICKABLE) ||
(viewFlags & CONTEXT_CLICKABLE) == CONTEXT_CLICKABLE) {
switch (action) {
case MotionEvent.ACTION_UP:
...
break;
case MotionEvent.ACTION_DOWN:
...
break;
case MotionEvent.ACTION_CANCEL:
...
break;
case MotionEvent.ACTION_MOVE:
...
break;
}
return true;
}
return false;
}
...
public boolean dispatchTouchEvent(MotionEvent event) {
...
if (onFilterTouchEventForSecurity(event)) {
//noinspection SimplifiableIfStatement
ListenerInfo li = mListenerInfo;
if (li != null && li.mOnTouchListener != null
&& (mViewFlags & ENABLED_MASK) == ENABLED
&& li.mOnTouchListener.onTouch(this, event)) {
result = true;
}
if (!result && onTouchEvent(event)) {
result = true;
}
}
...
}
...
事实上只有设置了点击回调函数/长按回调函数均会返回ture.所以也解释了为什么设置回调函数后super.onTouchEvent返回值变成true了.
仔细的同学可能发现了onClick回调函数是在ACTION_UP事件里面调用.这很符合我们使用习惯!哪一个软件不是松开手才调用按钮事件呢?具体情况是performClick函数负责调用onClick函数.
当然有更仔细的同学发现另一个问题了!super.dispatchTouchEvent在调用onTouchEvent函数之前会调用onTouch函数并且根据onTouch函数的返回值判断是否返回!!!这意味了什么?意味着如果你同时设置了onClick函数onTouch的情况下,如果onTouch返回false.那么一切都正常你不会发现什么很玄的东西.但是一旦你讲onTouch返回true.那么问题就会来了.onClick函数没有如愿的调用.就下下面展示的图片一样.
![这里写图片描述]()
专属山寨版
到这里我们摸透view派发事件的默认行为了,那么我们模仿来写一个属于我们理解的派发过程把!
“演示代码-5”
MainActivity.java
package com.dsliang.eventdispatch;
import android.app.Activity;
import android.os.Bundle;
import android.util.Log;
import android.view.MotionEvent;
import android.view.View;
public class MainActivity extends Activity {
public static String Tag = MainActivity.class.getSimpleName();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
View view = findViewById(R.id.viewEventDispatchView);
view.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
Log.d(Tag, "onClick");
}
});
view.setOnTouchListener(new View.OnTouchListener() {
@Override
public boolean onTouch(View view, MotionEvent motionEvent) {
Log.d(Tag, "onTouch");
return true;
}
});
}
}
EventDispatchView.java
package com.dsliang.eventdispatch;
import android.content.Context;
import android.util.AttributeSet;
import android.util.Log;
import android.view.MotionEvent;
import android.view.View;
/**
* Created by dsliang on 16-7-31.
*/
public class EventDispatchView extends View {
public static String Tag = EventDispatchView.class.getSimpleName();
public EventDispatchView(Context context) {
super(context);
}
public EventDispatchView(Context context, AttributeSet attrs) {
super(context, attrs);
}
public EventDispatchView(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
}
private OnTouchListener mTouchListener = null;
@Override
public void setOnTouchListener(OnTouchListener l) {
super.setOnTouchListener(l);
this.mTouchListener = l;
}
@Override
public boolean dispatchTouchEvent(MotionEvent event) {
boolean result;
Log.d(Tag, "dispatchTouchEvent: " + event.getAction());
if (null != this.mTouchListener && this.mTouchListener.onTouch(this, event)) {
return true;
}
result = doOnDispatchTouchEvent(event);
Log.d(Tag, "dispatchTouchEvent result: " + result);
return result;
}
private boolean doOnDispatchTouchEvent(MotionEvent event) {
return onTouchEvent(event);
}
public void callOnClickListener() {
if (isClickable()) {
performClick();
}
}
@Override
public boolean onTouchEvent(MotionEvent event) {
Log.d(Tag, "onTouchEvent: " + event.getAction());
if (isClickable() || isLongClickable()) {
switch (event.getAction()) {
case MotionEvent.ACTION_DOWN:
;
break;
case MotionEvent.ACTION_UP:
callOnClickListener();
break;
case MotionEvent.ACTION_MOVE:
;
break;
case MotionEvent.ACTION_CANCEL:
;
break;
}
return true;
}
return false;
}
}
activity_main.xml
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical">
<com.dsliang.eventdispatch.EventDispatchView
android:id="@+id/viewEventDispatchView"
android:layout_width="match_parent"
android:layout_height="60dp"
android:background="@android:color/darker_gray" />
</LinearLayout>
理论上现在我们的EventDispatchView控件就拥有了系统默认的行为了.(在事件派发方面)
现在然我们总结一下view在事件派发方面的几个关键地方:
1,事件派发首先调用doOnDispatchTouchEvent函数,然后调用onTouchEvent函数
2,根据ACTION_DOWN事件是否给消耗判,断接下来能否接收其余的一连串事件.
3,onClick回调函数在ACTION_UP事件中才调用
4,系统在没有设置点击回调函数/长按回调函数的情况下view不会消耗事件.(ACTION_DOWN事件)
5,onTouch回调函数的返回值会影响点击回调函数/长按回调函数的调用
作者:zq2114522 发表于2016/8/1 23:18:40
原文链接
 回到顶端
回到顶端








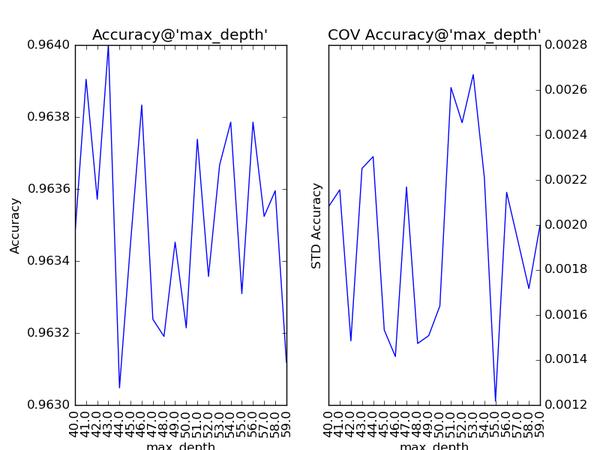
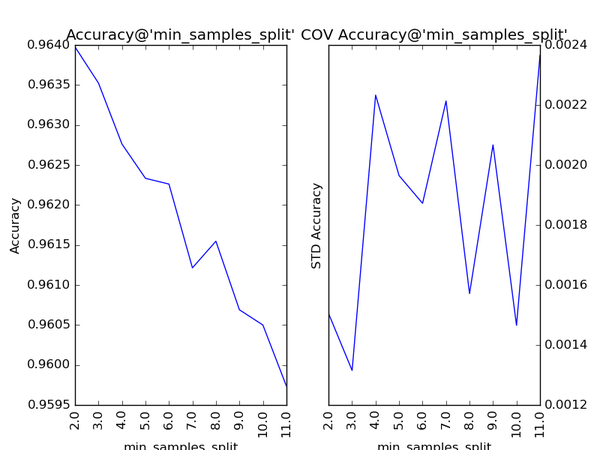
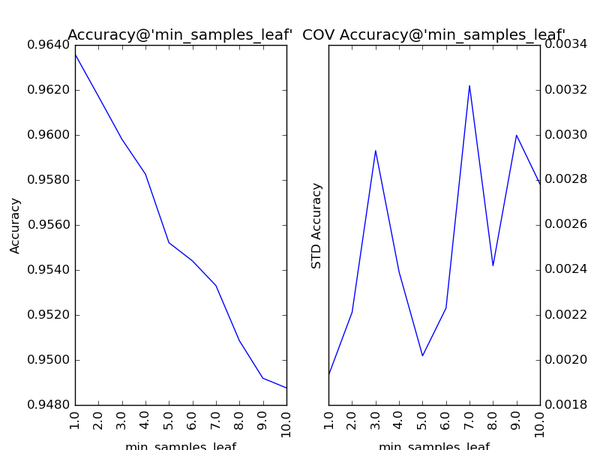
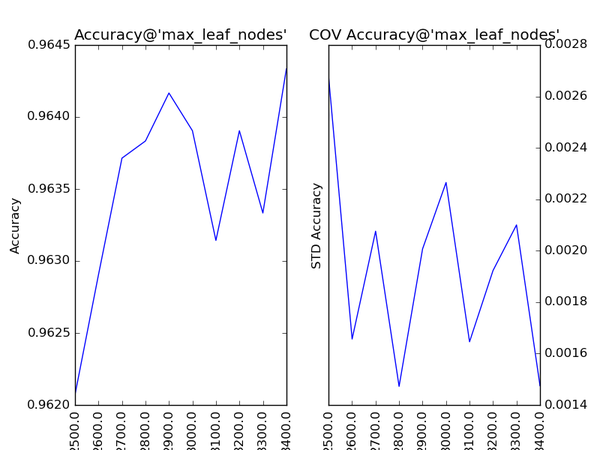
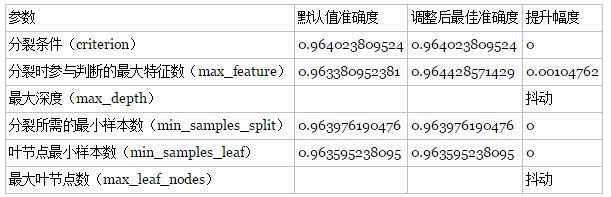
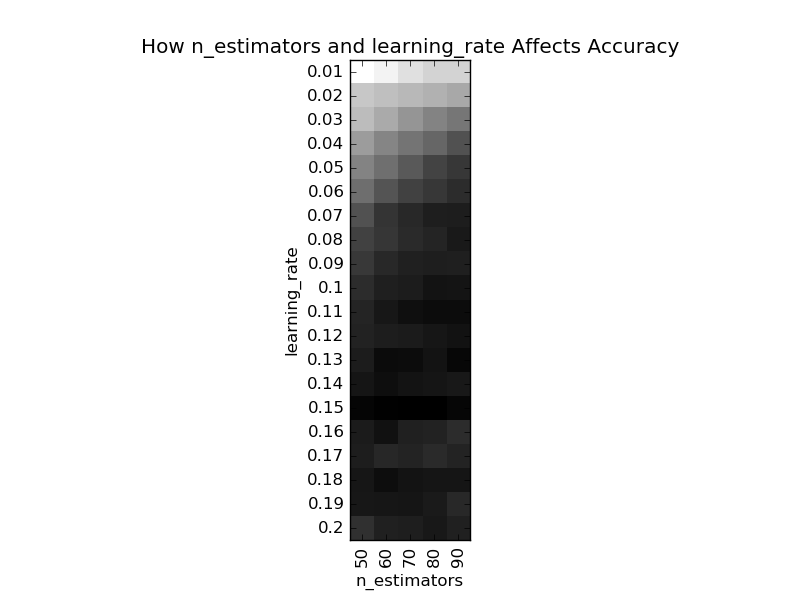
 对Gradient Tree Boosting来说,“子模型数”(n_estimators)和“学习率”(learning_rate)需要联合调整才能尽可能地提高模型的准确度:想象一下,A方案是走4步,每步走3米,B方案是走5步,每步走2米,哪个方案可以更接近10米远的终点?同理,子模型越复杂,对应整体模型偏差低,方差高,故“最大叶节点数”(max_leaf_nodes)、“最大树深度”(max_depth)等控制子模型结构的参数是与Random
Forest一致的。类似“分裂时考虑的最大特征数”(max_features),降低“子采样率”(subsample),也会造成子模型间的关联度降低,整体模型的方差减小,但是当子采样率低到一定程度时,子模型的偏差增大,将引起整体模型的准确度降低。还记得“初始模型”(init)是什么吗?不同的损失函数有不一样的初始模型定义,通常,初始模型是一个更加弱的模型(以“平均”情况来预测),虽说支持自定义,大多数情况下保持默认即可。在下图中,我们可以看到这些参数对Gradient Tree Boosting整体模型性能的影响:
对Gradient Tree Boosting来说,“子模型数”(n_estimators)和“学习率”(learning_rate)需要联合调整才能尽可能地提高模型的准确度:想象一下,A方案是走4步,每步走3米,B方案是走5步,每步走2米,哪个方案可以更接近10米远的终点?同理,子模型越复杂,对应整体模型偏差低,方差高,故“最大叶节点数”(max_leaf_nodes)、“最大树深度”(max_depth)等控制子模型结构的参数是与Random
Forest一致的。类似“分裂时考虑的最大特征数”(max_features),降低“子采样率”(subsample),也会造成子模型间的关联度降低,整体模型的方差减小,但是当子采样率低到一定程度时,子模型的偏差增大,将引起整体模型的准确度降低。还记得“初始模型”(init)是什么吗?不同的损失函数有不一样的初始模型定义,通常,初始模型是一个更加弱的模型(以“平均”情况来预测),虽说支持自定义,大多数情况下保持默认即可。在下图中,我们可以看到这些参数对Gradient Tree Boosting整体模型性能的影响: 2.3
一个朴实的方案:贪心的坐标下降法
2.3
一个朴实的方案:贪心的坐标下降法
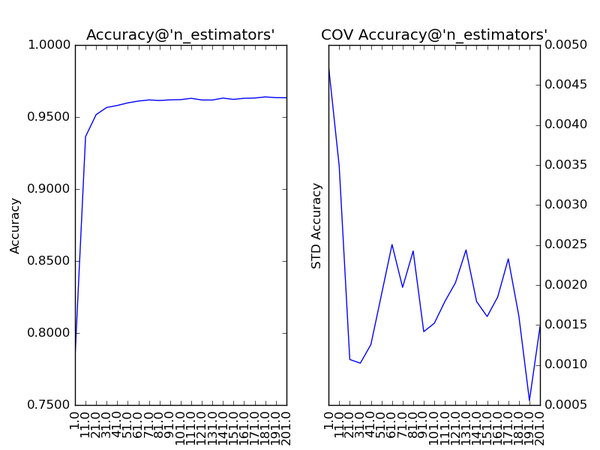
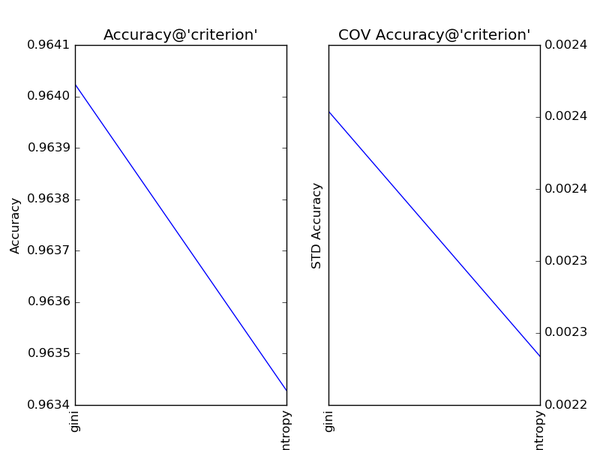
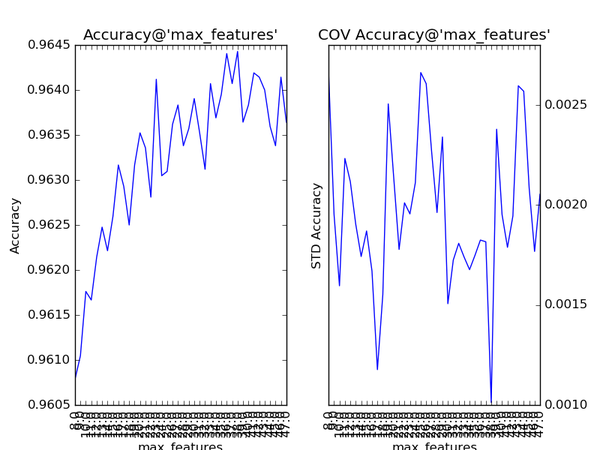
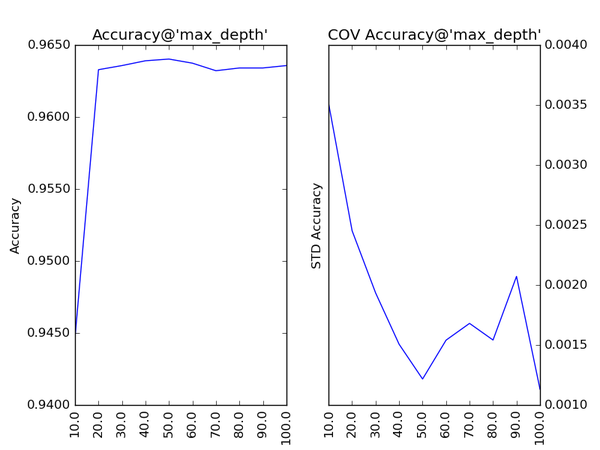 随着树的深度加深,子模型的偏差减少,整体模型的准确度得到提升。从理论上来说,子模型训练的后期,随着方差增大,子模型的准确度稍微降低,从而影响整体模型的准确度降低。看图中,似乎取值范围从40到60的情况可以印证这一观点。不妨以1为单位,设定取值范围为40到59,更加细致地分析:
随着树的深度加深,子模型的偏差减少,整体模型的准确度得到提升。从理论上来说,子模型训练的后期,随着方差增大,子模型的准确度稍微降低,从而影响整体模型的准确度降低。看图中,似乎取值范围从40到60的情况可以印证这一观点。不妨以1为单位,设定取值范围为40到59,更加细致地分析: