数据链接响应
sp<RILRequest> RIL::processSolicited(const Parcel& p) {
switch (rr->mRequest) {
case RIL_REQUEST_SETUP_DATA_CALL:
ret = responseSetupDataCall(p);
break;
}
…....
} else {
if (rr->mResult != NULL) {
AsyncResult::forMessage(rr->mResult, ret, NULL);
rr->mResult->sendToTarget();
}
}
}
sp<Object> RIL::responseSetupDataCall(const Parcel & p) {
dataCall = getDataCallResponse(p, ver);
return dataCall;
}
sp<DataCallResponse> RIL::getDataCallResponse(const Parcel & p, int32_t version) {
dataCall->status = p.readInt32();
dataCall->suggestedRetryTime = p.readInt32();
dataCall->cid = p.readInt32();
dataCall->active = p.readInt32();
dataCall->type = readString(p);
dataCall->ifname = readString(p);
sp<String> addresses = readString(p);
sp<String> dnses = readString(p);
sp<String> gateways = readString(p);
return dataCall;
}
bool DataConnection::DcActivatingState::processMessage(const sp<Message>& msg) {
switch (msg->what) {
case EVENT_SETUP_DATA_CONNECTION_DONE: {
DataCallResponse::SetupResult result = pDC->onSetupConnectionCompleted(ar);
switch (result.getValue()) {
case DataCallResponse::SetupResult::SUCCESS: {
pDC->mDcFailCause = DcFailCause::NONE;
pDC->transitionTo(pDC->mActiveState);
break;
}
}
}
}
DataCallResponse::SetupResult DataConnection::onSetupConnectionCompleted(const sp<AsyncResult>& ar) {
result = updateLinkProperty(response)->setupResult;
}
sp<DataConnection::UpdateLinkPropertyResult> DataConnection::updateLinkProperty(const sp<DataCallResponse>& newState) {
result->setupResult = setLinkProperties(newState, result->newLp);
}
void DataConnection::DcActiveState::enter() {
pDC->notifyAllOfConnected(Phone::REASON_CONNECTED());
}
void DataConnection::notifyAllOfConnected(const android::sp<String>& reason) {
notifyAllWithEvent(NULL, DctConstants::EVENT_DATA_SETUP_COMPLETE, reason);
}
void DcTrackerBase::handleMessage(const sp<Message>& msg) {
switch (msg->what) {
case DctConstants::EVENT_DATA_SETUP_COMPLETE:
mCidActive = msg->arg1;
onDataSetupComplete(safe_cast<AsyncResult*>(msg->obj));
break;
}
}
void DcTracker::onDataSetupComplete(const android::sp<AsyncResult>& ar) {
apnContext->setState(DctConstants::State::CONNECTED);
}
void MobileDataStateReceiver::onReceive(const sp<Context>& context, const sp<Intent>& intent) {
switch (state) {
case PhoneConstants::DataState::CONNECTED:
mdst->setDetailedState(NetworkInfo::DetailedState::CONNECTED, reason, apnName);
break;
}
}
void MobileDataStateTracker::setDetailedState(NetworkInfo::DetailedState state, const sp<String>& reason,const sp<String>& extraInfo) {
sp<Message>msg=mTarget->obtainMessage(NetworkStateTracker::EVENT_STATE_CHANGED,new NetworkInfo(mNetworkInfo));
msg->sendToTarget();
}
ConnectivityService.cpp
void ConnectivityService::MyHandler::handleMessage(const sp<Message>& msg) {
if (msg->what == NetworkStateTracker::EVENT_STATE_CHANGED) {
} else if (state == NetworkInfo::State::CONNECTED) {
mConnectivityService->handleConnect(info);
}
}
}
void ConnectivityService::handleConnect(const sp<NetworkInfo>& info) {
handleConnectivityChange(info, false);
}
void ConnectivityService::handleConnectivityChange(const sp<NetworkInfo>& replacedInfo, bool doReset) {
mNetIdtoInterfaces->put(ifa, new Integer(newNetId));
mNetd->createPhysicalNetwork(newNetId);
mNetd->addInterfaceToNetwork(ifa, newNetId);
bool resetDns = updateRoutes(newLp, curLp, (*mNetConfigs)[netType]->isDefault());
}
1、 addInterfaceToNetwork
NetworkManagementService.cpp
void NetworkManagementService::addInterfaceToNetwork(const android::sp<String> & iface, int netId) {
modifyInterfaceInNetwork(new String("add"), netId, iface);
}
void NetworkManagementService::modifyInterfaceInNetwork(const android::sp<String> & action, int netId, const android::sp<String> & iface) {
mConnector->doCommand(cmd, ret);
}
NativeDaemonConnector.cpp
Vector<sp<String> > NativeDaemonConnector::doCommand(const sp<String>& cmd, int & ret) {
return doCommandLocked(cmd, ret);
}
Vector<sp<String> > NativeDaemonConnector::doCommandLocked(const sp<String>& cmd, int& ret) {
bool rc = sendCommandLocked(newCmd);
}
bool NativeDaemonConnector::sendCommandLocked(const sp<String>& command) {
return sendCommandLocked(command, NULL);
}
bool NativeDaemonConnector::sendCommandLocked(const sp<String>& command, const sp<String>& argument) {
if (mOutputStream == NULL) {
return false;
} else {
mOutputStream->write(outCommand, 0, outCommand->length());
}
return true;
}
socket(netd)
这个socket是在NetlinkManager中创建的
CommandListener.cpp
int CommandListener::NetworkCommand::runCommand(SocketClient* client, int argc, char** argv) {
if (!strcmp(argv[2], "add")) {
if (int ret = sNetCtrl->addInterfaceToNetwork(netId, argv[4])) {
return operationError(client, "addInterfaceToNetwork() failed", ret);
}
} else if (!strcmp(argv[2], "remove")) {
if (int ret = sNetCtrl->removeInterfaceFromNetwork(netId, argv[4])) {
return operationError(client, "removeInterfaceFromNetwork() failed", ret);
}
}
}
NetworkController.cpp
int NetworkController::addInterfaceToNetwork(unsigned netId, const char* interface) {
RouteController::addInterfaceToLocalNetworkL(netId, interface);
return getNetworkLocked(netId)->addInterface(interface);
}
PhysicalNetwork.cpp
int PhysicalNetwork::addInterface(const std::string& interface) {
if (int ret = RouteController::addInterfaceToPhysicalNetwork(mNetId, interface.c_str(),
mPermission)) {
return ret;
}
return 0;
}
RouteController.cpp
int RouteController::addInterfaceToPhysicalNetwork(unsigned netId, const char* interface,
Permission permission) {
if (int ret = modifyPhysicalNetwork(netId, interface, permission, ACTION_ADD)) {
return ret;
}
updateTableNamesFile();
return 0;
}
WARN_UNUSED_RESULT int modifyPhysicalNetwork(unsigned netId, const char* interface,
Permission permission, bool add) {
uint32_t table = getRouteTableForInterface(interface);
if (table == RT_TABLE_UNSPEC) {
return -ESRCH;
}
if (int ret = modifyIncomingPacketMark(netId, interface, permission, add)) {
return ret;
}
if (int ret = modifyExplicitNetworkRule(netId, table, permission, INVALID_UID, INVALID_UID, add)) {
return ret;
}
if (int ret = modifyOutputInterfaceRule(interface, table, permission, INVALID_UID, INVALID_UID, add)) {
return ret;
}
return modifyImplicitNetworkRule(netId, table, permission, add);
}
WARN_UNUSED_RESULT int modifyExplicitNetworkRule(unsigned netId, uint32_t table,
Permission permission, uid_t uidStart,
uid_t uidEnd, bool add) {
return modifyIpRule(add ? RTM_NEWRULE : RTM_DELRULE, RULE_PRIORITY_EXPLICIT_NETWORK, table, fwmark.intValue, mask.intValue, IIF_NONE, OIF_NONE, uidStart, uidEnd);
}
WARN_UNUSED_RESULT int modifyIpRule(uint16_t action, uint32_t priority, uint32_t table,uint32_t fwmark, uint32_t mask, const char* iif, const char* oif, uid_t uidStart, uid_t uidEnd) {
for (size_t i = 0; i < ARRAY_SIZE(AF_FAMILIES); ++i) {
rule.family = AF_FAMILIES[i];
if (int ret = sendNetlinkRequest(action, flags, iov, ARRAY_SIZE(iov))) {
return ret;
}
}
}
int sendNetlinkRequest(uint16_t action, uint16_t flags, iovec* iov, int iovlen) {
int sock = socket(AF_NETLINK, SOCK_DGRAM, NETLINK_ROUTE);
if (sock != -1 &&
connect(sock, reinterpret_cast<const sockaddr*>(&NETLINK_ADDRESS),
sizeof(NETLINK_ADDRESS)) != -1 &&
writev(sock, iov, iovlen) != -1 &&
(ret = recv(sock, &response, sizeof(response), 0)) != -1) {
if (ret == sizeof(response)) {
ret = response.err.error;
}
}
2、 updateRoutes
ConnectivityService.cpp
bool ConnectivityService::updateRoutes(const sp<LinkProperties>& newLp, const sp<LinkProperties>& curLp, bool isLinkDefault) {
if (isLinkDefault || !(r->isDefaultRoute())) {
addRoute(newLp, r, TO_DEFAULT_TABLE);
} else {
addRoute(newLp, r, TO_SECONDARY_TABLE);
}
}
bool ConnectivityService::addRoute(const sp<LinkProperties>& p, const sp<RouteInfo>& r,
bool toDefaultTable) {
sp<String> pIfName = p->getInterfaceName();
return (pIfName, p, r, 0, ADD, toDefaultTable);
}
bool ConnectivityService::modifyRoute(const sp<String>& ifaceName, const sp<LinkProperties>& lp, const sp<RouteInfo>& r, int32_t cycleCount, bool doAdd, bool toDefaultTable) {
if (r->getDestination() != NULL && r->getDestination()->getNetworkPrefixLength() == 32 && prefixLength != 32) {
sp<LinkAddress> l = new LinkAddress(r->getDestination()->getAddress(), prefixLength);
sp<RouteInfo> ri = new RouteInfo(l, r->getGateway());
mAddedRoutes->add(ri);
mNetd->addRoute(ifaceName,netId, ri);
} else {
mAddedRoutes->add(r);
mNetd->addRoute(ifaceName,netId, r);
}
}
void NetworkManagementService::addRoute(const android::sp<String> & ifname,int32_t netId, const sp<RouteInfo>& route) {
modifyRoute(ifname, netId, mADD, route, DEFAULT());
}
void NetworkManagementService::modifyRoute(const android::sp<String> & ifname, int32_t netId, int32_t action, const sp<RouteInfo>& route, const sp<String>& type) {
Vector<sp<String> > rsp = mConnector->doCommand(cmd->toString(), ret);
}
NativeDaemonConnector.cpp
Vector<sp<String> > NativeDaemonConnector::doCommand(const sp<String>& cmd, int & ret) {
return doCommandLocked(cmd, ret);
}
Vector<sp<String> > NativeDaemonConnector::doCommandLocked(const sp<String>& cmd, int& ret) {
bool rc = sendCommandLocked(newCmd);
}
bool NativeDaemonConnector::sendCommandLocked(const sp<String>& command) {
return sendCommandLocked(command, NULL);
}
bool NativeDaemonConnector::sendCommandLocked(const sp<String>& command, const sp<String>& argument) {
if (mOutputStream == NULL) {
return false;
} else {
mOutputStream->write(outCommand, 0, outCommand->length());
}
return true;
}
socket(netd)
这个socket是在NetlinkManager中创建的
CommandListener.cpp
int CommandListener::NetworkCommand::runCommand(SocketClient* client, int argc, char** argv) {
if (add) {
ret = sNetCtrl->addRoute(netId, interface, destination, nexthop, legacy, uid);
} else {
ret = sNetCtrl->removeRoute(netId, interface, destination, nexthop, legacy, uid);
}
}
NetworkController.cpp
int NetworkController::addRoute(unsigned netId, const char* interface, const char* destination,
const char* nexthop, bool legacy, uid_t uid) {
return modifyRoute(netId, interface, destination, nexthop, true, legacy, uid);
}
int NetworkController::modifyRoute(unsigned netId, const char* interface, const char* destination,
const char* nexthop, bool add, bool legacy, uid_t uid) {
if(add) {
RouteController::addRoute(interface, destination, nexthop, RouteController::LOCAL_NETWORK);
} else {
RouteController::removeRoute(interface, destination, nexthop, RouteController::LOCAL_NETWORK);
}
}
RouteController.cpp
int RouteController::addRoute(const char* interface, const char* destination, const char* nexthop,
TableType tableType) {
return modifyRoute(RTM_NEWROUTE, interface, destination, nexthop, tableType);
}
int modifyRoute(uint16_t action, const char* interface, const char* destination, const char* nexthop, RouteController::TableType tableType) {
int ret = modifyIpRoute(action, table, interface, destination, nexthop);
return 0;
}
int modifyIpRoute(uint16_t action, uint32_t table, const char* interface,
const char* destination, const char* nexthop) {
return sendNetlinkRequest(action, flags, iov, ARRAY_SIZE(iov));
}
int sendNetlinkRequest(uint16_t action, uint16_t flags, iovec* iov, int iovlen) {
int sock = socket(AF_NETLINK, SOCK_DGRAM, NETLINK_ROUTE);
if (sock != -1 &&
connect(sock, reinterpret_cast<const sockaddr*>(&NETLINK_ADDRESS),
sizeof(NETLINK_ADDRESS)) != -1 &&
writev(sock, iov, iovlen) != -1 &&
(ret = recv(sock, &response, sizeof(response), 0)) != -1) {
if (ret == sizeof(response)) {
ret = response.err.error;
}
}
注:socket(AF_NETLINK, SOCK_DGRAM, NETLINK_ROUTE); 套接字AF_NETLINK,则是用于与kernel通讯的接口。通过向量IO向kernel中发送 iov数据,并同时接收响应,错误处理。
NETD
Android5.0之后,网络的功能实现完全转移到netd上面,主要包括ip,路由配置,dns代理设置,带宽控制和流量统计等。
下面是Netd框架示意图,NetworkManagerService和NativeDeamonConnect是java代码,NetworkManagerService作为service随系统启动,java层所有对网络的操作都通过它来完成。
其他都是c++代码,主要完成两个工作:
1、接收上层的命令,完成指定对网络的操作;
2、接收kernel netlink信息,传递到上层。
接收上层命令的工作,通过4个socket完成:
/dev/socket/netd ————– CommandListener
/dev/socket/dnsproxyd ————– DnsproxyListener
/dev/socket/mdns –————– MdnsSdListener
/dev/socket/fwmarkd –————– FwmarkServer
CommandListener接收配置ip,路由,iptables的命令
DnsproxyListener接收查询dns的操作
MdnsSdListener接收针对mdnsd的操作
FwmarkServer用于对特定的socket设置mark值
![这里写图片描述]()
下图是Netlink部分,模块调用关系示例NetlinkManager启动3个socket,用于监听3种不同的event:Uevent,RouteEvent,QuotaEvent。 通过SocketListener实现监听功能,netlink信息,最终通过/dev/socket/netd送到 NetworkManagementService(java代码),分配到注册到它里面的各个观察者实例(Ethernet,wifi等)。
![这里写图片描述]()
作者:xiabodan 发表于2016/12/20 18:45:43
原文链接


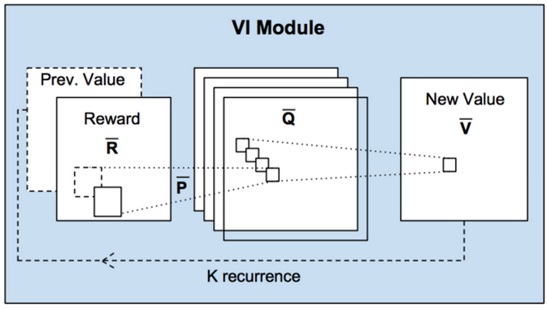
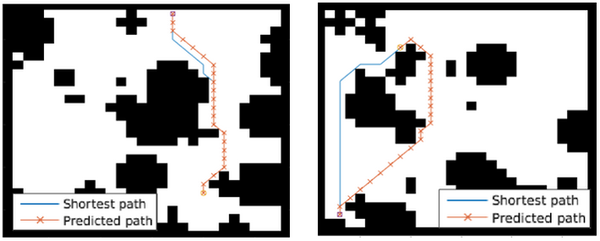
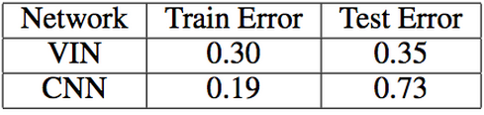 在将其同CNN,以及FCN网络的能力进行比较。分别在三种不同大小的Grid上面进行了比较,VIN网络的能力均超过了其余两种,越复杂的问题当中优势越明显。
在将其同CNN,以及FCN网络的能力进行比较。分别在三种不同大小的Grid上面进行了比较,VIN网络的能力均超过了其余两种,越复杂的问题当中优势越明显。

![[LoliHouse] Princess-Session Orchestra - 15 [WebRip 1080p HEVC-10bit...](http://s2.loli.net/2025/04/09/QO618K72ytGZmDJ.webp)







